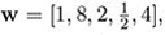Database Reference
In-Depth Information
The next two training examples,
d
and
e
, require no change, since they are correctly clas-
sified. However, there is a problem with
f
= [1, 0, 1, 1, 0], since
w
.
f
= 6 >
θ
, while the
associated label for
f
is −1. Thus, we must divide the first, third, and fourth components of
w
by 2, since these are the components where
f
has 1. The new value of
w
is [1, 4, 1, 1, 2].
We still have not converged. It turns out we must consider each of the training examples
a
through
f
again. At the end of this process, the algorithm has converged to a weight vector
which with threshold
θ
= 5 correctly classifies all of the training ex-
This figure gives the associated label
y
and the computed dot product of
w
and the given
feature vector. The last five columns are the five components of
w
after processing each
training example.
□
Figure 12.7
Sequence of updates to
w
performed by the Winnow Algorithm on the training set of
Fig. 12.6
12.2.4
Allowing the Threshold to Vary
Suppose now that the choice of threshold 0, as in
Section 12.2.1
, or threshold
d
, as in
Sec-
tion 12.2.3
is not desirable, or that we don't know the best threshold to use. At the cost of
adding another dimension to the feature vectors, we can treat
θ
as one of the components
of the weight vector
w
. That is:
(1) Replace the vector of weights
w
= [
w
1
,
w
2
, . . . ,
w
d
] by
w
′ = [
w
1
,
w
2
, . . . ,
w
d
,
θ
]
(2) Replace every feature vector
x
= [
x
1
,
x
2
, . . . ,
x
d
] by
x
′ = [
x
1
,
x
2
, . . . ,
x
d
, −1]
Then, for the new training set and weight vector, we can treat the threshold as 0 and
use the algorithm of
Section 12.2.1
.
The justification is that
w
′.
x
′ ≥ 0 is equivalent to
which in turn is equivalent to
w
.
x
≥
θ
. The latter is the condition for a positive
response from a perceptron with threshold
θ
.