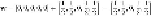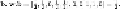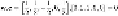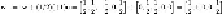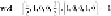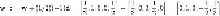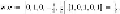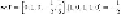Database Reference
In-Depth Information
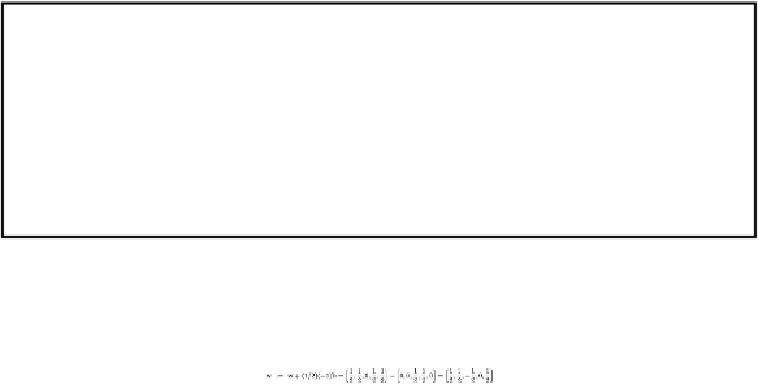
w
.
a
= 0. Since 0 is not positive, we move
w
in the direction of
a
by performing
w
:=
w
+
(1/2)(+1)
a
. The new value of
w
is thus
Pragmatics of Training on Emails
When we represent emails or other large documents as training examples, we would not really want to construct the
vector of 0's and 1's with a component for every word that appears even once in the collection of emails. Doing so
would typically give us sparse vectors with millions of components. Rather, create a table in which all the words ap-
pearing in the emails are assigned integers 1, 2, . . ., indicating their component. When we process an email in the
training set, make a list of the components in which the vector has 1; i.e., use the standard sparse representation for
the vector. If we eliminate stop words from the representation, or even eliminate words with a low TF.IDF score, then
we make the vectors representing emails significantly sparser and thus compress the data even more. Only the vector
w
needs to have all its components listed, since it will not be sparse after a small number of training examples have
been processed.
Next, consider
Since the associated
y
for
b
is −1,
b
is misclassified. We
thus assign
Training example
c
is next. We compute
Since the associated
y
for
c
is +1,
c
is also misclassified. We thus assign
Training example
d
is next to be considered:
Since the associated
y
for
d
is −1,
d
is misclassified as well. We thus assign
For training example
e
we compute Since the associated
y
for
e
is +1,
e
is
classified correctly, and no change to
w
is made. Similarly, for
f
we compute
so
f
is correctly classified. If we check
a
through
d
, we find that this
w
correctly classifies
them as well. Thus, we have converged to a perceptron that classifies all the training set
examples correctly. It also makes a certain amount of sense: it says that “viagra” and “ni-