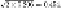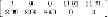Database Reference
In-Depth Information
EXAMPLE
11.13 Let
r
= 2 for our CUR-decomposition. Suppose that our random selection
of columns from matrix
M
of
Fig. 11.12
is first
Alien
(the second column) and then
Cas-
ablanca
(the fourth column). The column for
Alien
is [1, 3, 4, 5, 0, 0, 0]
T
, and we must
scale this column by dividing by Recall from
Example 11.12
that the probability associ-
ated with the
Alien
column is .210, so the division is by To two decimal places, the
scaled column for
Alien
is [1.54, 4.63, 6.17, 7.72, 0, 0, 0]
T
. This column becomes the first
column of
C
.
The second column of
C
is constructed by taking the column of
M
for Casablanca, which
is [0, 0, 0, 0, 4, 5, 2]
T
, and dividing it by 0.430. Thus, the second column of
C
is
[0, 0, 0, 0, 9.30, 11.63, 4.65]
T
to two decimal places.
Now, let us choose the rows for
R
. The most likely rows to be chosen are those for Jenny
and Jack, so let's suppose these rows are indeed chosen, Jenny first. The unscaled rows for
R
are thus
To scale the row for Jenny, we note that its associated probability is 0.206, so we divide
by
To scale the row for Jack, whose associated probability is 0.309, we divide by
Thus, the matrix
R
is
□
11.4.3
Constructing the Middle Matrix
Finally, we must construct the matrix
U
that connects
C
and
R
in the decomposition. Recall
that
U
is an
r
×
r
matrix. We start the construction of
U
with another matrix of the same
size, which we call
W
. The entry in row
i
and column
j
of
W
is the entry of
M
whose row is
the one from which we selected the
i
th row of
R
and whose column is the one from which
we selected the
j
th column of
C
.
EXAMPLE
11.14 Let us follow the selections of rows and columns made in
Example 11.13
.
We claim
The first row of
W
corresponds to the first row of
R
, which is the row for Jenny in the
matrix
M
of
Fig. 11.12
. The 0 in the first column is there because that is the entry in the row
of
M
for Jenny and the column for
Alien
; recall that the first column of
C
was constructed