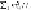Database Reference
In-Depth Information
measure of importance we must use is the square of the Frobenius norm, that is, the sum
of the squares of the elements of the row or column. Let the square of the Frobenius
norm of
M
. Then each time we select a row, the probability
p
i
with which we select row
i
is
Each time we select a column, the probability
q
j
with which we select column
j
is
Fig. 11.12
.
The sum of the squares of the elements of
M
is 243. The three columns for the
science-fiction movies
The Matrix
,
Alien
, and
Star Wars
each have a squared Frobenius
norm of 1
2
+ 3
2
+ 4
2
+ 5
2
= 51, so their probabilities are each 51/243 = .210. The remaining
two columns each have a squared Frobenius norm of 4
2
+ 5
2
+ 2
2
= 45, and therefore their
probabilities are each 45/243 = .185.
Figure 11.12
The matrix
M
, repeated from
Fig. 11.6
The seven rows of
M
have squared Frobenius norms of 3, 27, 48, 75, 32, 50, and 8, re-
spectively. Thus, their respective probabilities are .012, .111, .198, .309, .132, .206, and
.033.
□
Now let us select
r
columns for the matrix
C
. For each column, we choose randomly
from the columns of
M
. However, the selection is not with uniform probability; rather, the
j
th column is selected with probability
q
j
. Recall that probability is the sum of the squares
of the elements in that column divided by the sum of the squares of all the elements of the
matrix. Each column of
C
is chosen independently from the columns of
M
, so there is some
chance that a column will be selected more than once. We shall discuss how to deal with
this situation after explaining the basics of CUR-decomposition.
Having selected each of the columns of
M
, we scale each column by dividing its ele-
ments by the square root of the expected number of times this column would be picked.
That is, we divide the elements of the
j
th column of
M
, if it is selected, by The scaled
column of
M
becomes a column of
C
.
Rows of
M
are selected for
R
in the analogous way. For each row of
R
we select from
the rows of
M
, choosing row
i
with probability
p
i
. Recall
p
i
is the sum of the squares of the
elements of the
i
th row divided by the sum of the squares of all the elements of
M
. We then
scale each chosen row by dividing by if it is the
i
th row of
M
that was chosen.