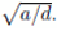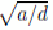Database Reference
In-Depth Information
If we choose to normalize
M
, then when we make predictions, we need to undo the nor-
malization. That is, if whatever prediction method we use results in estimate
e
for an ele-
ment
m
ij
of the normalized matrix, then the value we predict for
m
ij
in the true utility matrix
is
e
plus whatever amount was subtracted from row
i
and from column
j
during the normal-
ization process.
Initialization
As we mentioned, it is essential that there be some randomness in the way we seek an op-
timum solution, because the existence of many local minima justifies our running many
different optimizations in the hope of reaching the global minimum on at least one run. We
can vary the initial values of
U
and
V
, or we can vary the way we seek the optimum (to be
discussed next), or both.
A simple starting point for
U
and
V
is to give each element the same value, and a good
choice for this value is that which gives the elements of the product
UV
the average of the
nonblank elements of
M
. Note that if we have normalized
M
, then this value will neces-
sarily be 0. If we have chosen
d
as the lengths of the short sides of
U
and
V
, and
a
is the
average nonblank element of
M
, then the elements of
U
and
V
should be
If we want many starting points for
U
and
V
, then we can perturb the value ran-
domly and independently for each of the elements. There are many options for how we do
the perturbation. We have a choice regarding the distribution of the difference. For example
we could add to each element a normally distributed value with mean 0 and some chosen
standard deviation. Or we could add a value uniformly chosen from the range −
c
to +
c
for
some
c
.
Performing the Optimization
In order to reach a local minimum from a given starting value of
U
and
V
, we need to pick
an order in which we visit the elements of
U
and
V
. The simplest thing to do is pick an
order, e.g., row-by-row, for the elements of
U
and
V
, and visit them in round-robin fash-
ion. Note that just because we optimized an element once does not mean we cannot find
a better value for that element after other elements have been adjusted. Thus, we need to
visit elements repeatedly, until we have reason to believe that no further improvements are
possible.
Alternatively, we can follow many different optimization paths from a single starting
value by randomly picking the element to optimize. To make sure that every element is
considered in each round, we could instead choose a permutation of the elements and fol-
low that order for every round.