Database Reference
In-Depth Information
outcome. We shall not consider this option here, but give a simple hypothetical example of
a decision tree.
EXAMPLE
9.6 Suppose our items are news articles, and features are the high-TF.IDF words
(
keywords
) in those documents. Further suppose there is a user
U
who likes articles about
baseball, except articles about the New York Yankees. The row of the utility matrix for
U
has 1 if
U
has read the article and is blank if not. We shall take the 1s as “like” and the
blanks as “doesn't like.” Predicates will be boolean expressions of keywords.
Since
U
generally likes baseball, we might find that the best predicate for the root is
“homerun” OR (“batter” AND “pitcher”). Items that satisfy the predicate will tend to be
positive examples (articles with 1 in the row for
U
in the utility matrix), and items that fail
to satisfy the predicate will tend to be negative examples (blanks in the utility-matrix row
for
U
).
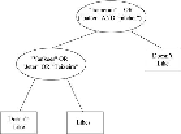
Figure 9.3
shows the root as well as the rest of the decision tree.
Figure 9.3
A decision tree
Suppose that the group of articles that do not satisfy the predicate includes sufficiently
few positive examples that we can conclude all of these items are in the “don't-like” class.
We may then put a leaf with decision “don't like” as the right child of the root. However,
the articles that satisfy the predicate includes a number of articles that user
U
doesn't like;
these are the articles that mention the Yankees. Thus, at the left child of the root, we build
another predicate. We might find that the predicate “Yankees” OR “Jeter” OR “Teixeira” is
the best possible indicator of an article about baseball and about the Yankees. Thus, we see
in
Fig. 9.3
the left child of the root, which applies this predicate. Both children of this node
are leaves, since we may suppose that the items satisfying this predicate are predominantly
negative and those not satisfying it are predominantly positive.
□
Unfortunately, classifiers of all types tend to take a long time to construct. For instance,
if we wish to use decision trees, we need one tree per user. Constructing a tree not only
requires that we look at all the item profiles, but we have to consider many different pre-
dicates, which could involve complex combinations of features. Thus, this approach tends
to be used only for relatively small problem sizes.