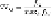Database Reference
In-Depth Information
1.3.1
Importance of Words in Documents
In several applications of data mining, we shall be faced with the problem of categorizing
documents (sequences of words) by their topic. Typically, topics are identified by finding
the special words that characterize documents about that topic. For instance, articles about
baseball would tend to have many occurrences of words like “ball,” “bat,” “pitch,”, “run,”
and so on. Once we have classified documents to determine they are about baseball, it is
not hard to notice that words such as these appear unusually frequently. However, until we
have made the classification, it is not possible to identify these words as characteristic.
Thus, classification often starts by looking at documents, and finding the significant
words in those documents. Our first guess might be that the words appearing most fre-
quently in a document are the most significant. However, that intuition is exactly opposite
of the truth. The most frequent words will most surely be the common words such as “the”
or “and,” which help build ideas but do not carry any significance themselves. In fact, the
several hundred most common words in English (called
stop words
) are often removed
from documents before any attempt to classify them.
In fact, the indicators of the topic are relatively rare words. However, not all rare words
are equally useful as indicators. There are certain words, for example “notwithstanding” or
“albeit,” that appear rarely in a collection of documents, yet do not tell us anything use-
ful. On the other hand, a word like “chukker” is probably equally rare, but tips us off that
the document is about the sport of polo. The difference between rare words that tell us
something and those that do not has to do with the concentration of the useful words in just
a few documents. That is, the presence of a word like “albeit” in a document does not make
it terribly more likely that it will appear multiple times. However, if an article mentions
“chukker” once, it is likely to tell us what happened in the “first chukker,” then the “second
chukker,” and so on. That is, the word is likely to be repeated if it appears at all.
The formal measure of how concentrated into relatively few documents are the occur-
rences of a given word is called TF.IDF (
Term Frequency times Inverse Document Fre-
quency
). It is normally computed as follows. Suppose we have a collection of
N
documents.
Define
f
ij
to be the
frequency
(number of occurrences) of term (word)
i
in document
j
. Then,
define the
term frequency TF
ij
to be:
That is, the term frequency of term
i
in document
j
is
f
ij
normalized by dividing it by the
maximum number of occurrences of any term (perhaps excluding stop words) in the same
document. Thus, the most frequent term in document
j
gets a TF of 1, and other terms get
fractions as their term frequency for this document.