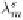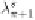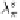Database Reference
In-Depth Information
7.1 The Prefix Filter
Let
≺
be a total ordering of the token universe Λ, such that for
λ
1
,λ
2
W
(
λ
2
) (i.e., tokens are sorted in non-
increasing order of their weights). Consider Weighted Intersection sim-
ilarity first and assume that we are treating strings as sets (disregarding
token frequency and position) for simplicity of presentation. The prefix
signature of a string is defined as
∈
Λ
,λ
1
≺
λ
2
⇔
W
(
λ
1
)
≥
Definition 7.1 (Weighted Intersection Prefix).
Let
s
=
{λ
1
,...
,
λ
s
m
}
represented as a set of tokens, where without loss of generality
tokens are sorted in increasing
λ
s
m
). Let
θ
be a
pre-determined minimum possible query threshold for Weighted Inter-
section similarity. Let
λ
π
be the token in
s
s.t.
order (i.e.,
λ
1
≺ ··· ≺
≺
m
W
(
λ
i
)
π
= arg max
1
≤π≤m
≥
θ.
i
=
π
P
θ
(
s
) of string
s
is defined as
P
θ
(
s
)=
λ
1
,...,λ
π
}
The prefix
{
, and the
S
θ
(
s
) is defined as
S
θ
(
s
)=
λ
π
+1
,...,λ
s
m
}
sux
{
.
λ
1
,...,λ
s
m
}
For example, the prefix and sux of string
s
=
{
are
shown in Figure 7.1.
It holds that
P
θ
(
s
)
,
P
θ
(
r
)
Lemma 7.1.
Given two string prefixes
⇒P
θ
(
s
)
∩P
θ
(
r
)
I
(
s, r
)
≥
θ
∅
.
=
Proof.
The intuition behind the proof is shown in Figure 7.2. The proof
is by contradiction. Let
P
θ
(
s
)
∩P
θ
(
r
)=
I
(
s, r
)
≥
θ
and
∅
. Notice that
Fig. 7.1 The prefix and sux of string
s
=
{λ
1
,...,λ
s
m
}
. Without loss of generality, it is
assumed that
W
(
λ
1
)
≥ ... ≥ W
(
λ
s
m
).