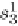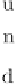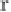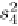Database Reference
In-Depth Information
edit distance
θ
from the query and traverse the trie using all resulting
queries. Inversely, one can generate all possible strings within edit
distance
θ
from the data strings and pre-construct a trie on the
augmented dataset. Clearly, the first approach has very high query
cost and the second a very high space cost.
A better approach is to compute an active set of trie nodes incre-
mentally, by considering all prefixes of the query, starting from the
empty string
∅
. An active node is one that corresponds to a trie string
that is within edit distance
θ
from the current prefix of the query string.
Consider the trie in Figure 8.1 and query string
v
= 'Found' with
θ
=1.
For simplicity we denote each node in the tree using the full string cor-
responding to that node; in practice only a node identifier is used to
conserve space. The active nodes for each prefix of
v
, along with their
edit distance from that prefix, are shown in Table 8.1.
Let
N
be a node in the trie. Denote with
σ
(
N
) the label of the
node, and with
s
(
N
) the full string corresponding to that node (i.e.,
the sequence of labels in the path from the root of the trie to node
N
).
Denote with
v
i
=
σ
1
, the
i
length prefix of query
v
(let
v
0
denote the empty string), and let
A
i
denote the set of active
nodes in the trie for query prefix
v
i
. Let every entry of
A
i
be a pair
(
N,
···
σ
i
,
0
≤
i
≤|
v
|
(
s
(
N
)
,v
i
)). We initialize
A
0
for prefix
v
0
=
by adding the root
node of the trie. The root corresponds to the empty string
∅
as well
E
∅
c
f
u
h
e
o
u
n
i
e
o
n
i
l
d
d
d
c
d
e
f
Fig. 8.1 A simple trie stricture.