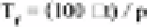Environmental Engineering Reference
In-Depth Information
Figure 12.2. Graphical presentation of
the cumulative probability of data sets
with a normal distribution and a
different number of observations.
(12.2)
where: T
r
= return period; □t = sampling interval; p = probability of being exceeded.
The application of these basic statistical concepts to a specific data set reflecting the
observed values during continuous and regular monitoring of water quality, would help in
a correct interpretation of the results and correspondingly, a correct assessment of the
water quality status at this specific location. For an example, if the results of an arbitrary
monitoring program, measuring ammonia at a frequency of once per month for a duration
of one year, the data set would be composed by 12 values. The value representing the
ammonia concentration during the year would be the maximum concentration at 95%
cumulative probability, which could be expected to be exceeded by 5% of the observed
values only. Then the frequency of the expected occurrence of the extreme value at this
specific point would be equal to 20 months (from equation 12.2), given that p = 5% and
□t = 1 month. This example shows the need to link the monitoring process and related
assessments with existing regulatory instruments.
The case studies presented in previous chapters, usually use mean values for the
evaluation and assessment of water quality. Due to the time and resources limitations, the
number of observations in some cases were too low, and usually a high variability of the
data sets were observed, deviating from the normal distribution. This would require the
application of statistical transformations and the use of more complex statistical tools,
which were not available. In addition, the existing regulatory instruments include specific
limits and criteria as fixed numerical values, but do not prescribe requirements with
respect to the frequency of observations and the statistical analysis of the data obtained,