Information Technology Reference
In-Depth Information
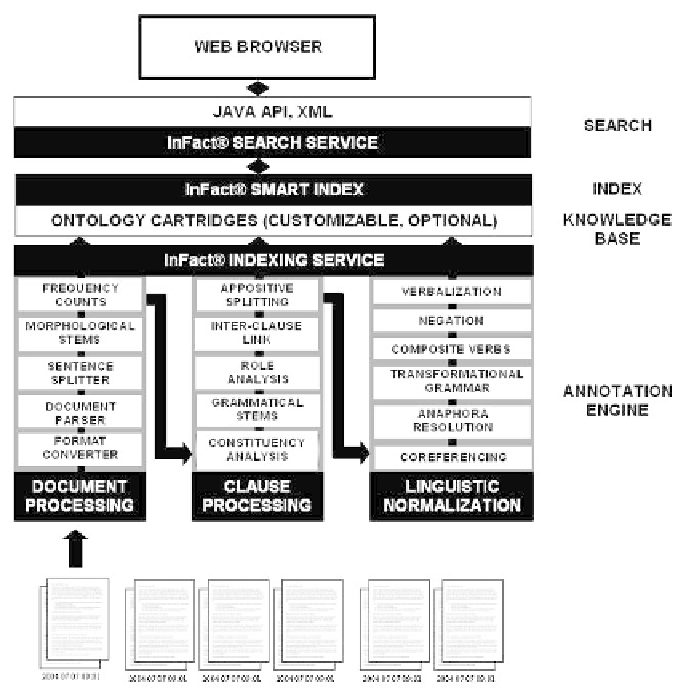
Fig. 5.1.
Functional overview of InFact.
Document Processing
The first step in document processing is format conversion, which we handle through
our native format converters, or optionally via search export conversion software
from Stellant
TM
(www.stellent.com), which can convert 370 different input file types.
Our customized document parsers can process disparate styles and recognized zones
within each document. Customized document parsers address the issue that a Web
page may not be the basic unit of content, but it may consist of separate sections
with an associated set of relationships and metadata. For instance a blog post may
contain blocks of text with different dates and topics. The challenge is to automat-
ically recognize variations from a common style template, and segment information
in the index to match zones in the source documents, so the relevant section can
be displayed in response to a query. Next we apply logic for sentence splitting in
preparation for clause processing. Challenges here include the ability to unambigu-
ously recognize sentence delimiters, and recognize regions such as lists or tables that
Search WWH ::

Custom Search