Information Technology Reference
In-Depth Information
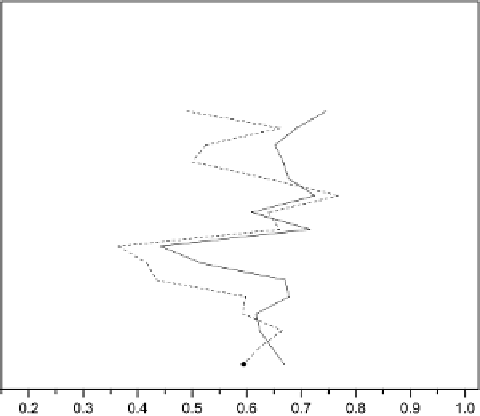
Fig. 10.4.
Performance of16weightingschemes over 6 minor categories in MCV1,
whereeach ofthem only occupies around 1% ofMCV1
higher than CBTW
1
, the averagedrecall of CBTW
1
reaches 0.9080, comparedwith
TFIDF's0.7935.
10.6.3 Significance Test
In orderto determine whetherthe performance improvement gained by CBTWs and
otherTFFVsoverthese two imbalanced data sets aresignificant, we performedthe
macrosigntest (S-test) and macro t-test (T-test)onthe paired
F
1
values. Table
10.6 and 10.7 showthe detailed
F
1
values of each individualcategory generated
based ondifferent majorterm weighting approaches over MCV1 and Reuters-21578,
respectively. As pointed out by Yang[46],ontheone hand, the S-testmaybe more
robustinreducing the influence of outliers, but at the risk ofbeing insensitiveor
not su
ciently sensitive in performance comparisonbecause it ignores the absolute
difference between
F
1
values; ontheother hand, the T-testissensitive to the absolute
values, but couldbeoverly sensitive when
F
1
values are highlyunstable, e.g., for
the minor categories. Therefore, we adopt both tests here togive a comprehensive
understandingofthe performance improvement.
Since forboth data sets, TFIDF performs better than theothertwoclassic
approaches and CBTW
1
achieves the best overall performance comparedtoother
CBTWs and TFFVs, wechoose themas the representatives oftheir peers. For






































































































Search WWH ::

Custom Search