Information Technology Reference
In-Depth Information
tion and guided operations to ensure that the produced offspring are semantically
coherent.
In order to deal with issues regarding representation and new genetic operations
so to produce an effective KDT process, our working model has been divided into
two phases. The first phase is the preprocessing step aimed to produce both training
information for further evaluation and the initial population of the GA. The second
phase constitutes the knowledge discovery itself, in particular this aims at producing
and evaluating explanatory unseen hypotheses.
The whole processing starts by performing the IE task (Figure 9.1) which applies
extraction patterns and then generates a rule-like representation for each document
of the specific domain corpus. After processing a set of
n
documents, the extraction
stage will produce
n
rules, each one representing the document's content in terms of
its conditions and conclusions. Once generated, these rules, along with other training
data, become the “model” which will guide the GA-based discovery (see Figure 9.1).
IE task
Rule 1
Doc 1
Part-of-Speech
Tagger
Doc 2
Rule 2
Hypothesis 1
Hypothesis 2
....
Hypothesis k
(k << p)
Doc 3
GA
Role and
Predicate
Rule 3
.
Preprocessed
Data
Hypothesis 3
.
.
Learning
Recognition
.
.
Doc n
Rule n
Domain Corpus
Discovered
Novel Hypotheses
Hypothesis 1
Hypothesis 2
....
....
Hypothesis p
(p << n)
Document
Representation
Initial
LSA training
Population
Knowledge Discovery
Preprocessing and Training
Fig. 9.1.
The Evolutionary Model for Knowledge Discovery from Texts
In order to generate an initial set of hypotheses, an initial population is created
by building random hypotheses from the initial rules, that is, hypotheses containing
predicate and rhetorical information from the rules are constructed. The GA then
runs for a number of generations until a fixed number of generations is achieved. At
the end, a small set of the best hypotheses are obtained.
The description of the model is organised as follows: Section 9.3.1 presents the
main features of the text preprocessing phase and how the representation for the
hypotheses is generated. In addition, training tasks which generate the initial knowl-
edge (semantic and rhetorical information) to feed the discovery are described. Sec-
tion 9.3.2 describes constrained genetic operations to enable the hypotheses dis-
covery, and proposes different evaluation metrics to assess the plausibility of the
discovered hypotheses in a multi-objective context.

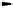







Search WWH ::

Custom Search