Information Technology Reference
In-Depth Information
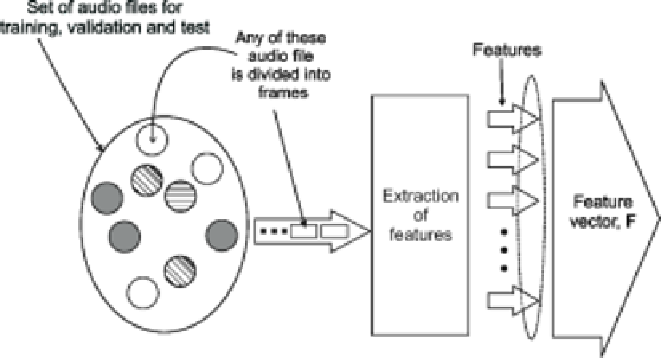
Fig. 4.
The feature extraction process
the features on the DSP core should require a sufficiently small number of basic
mathematical operations per second. The process of computing the features is called
'feature extraction', and is displayed in Figure 4.
The feature extraction requires dividing the sound signal into shorter parts called
'frames'. After a sequence of mathematical operations, the feature extractor produces
a number of sound describing features that form the vector
F
, the information of
which the classifier makes use.
The feature extraction process can be the most time-consuming task in the classifica-
tion system. It is very important therefore to carefully design and select the features that
will be calculated, taking into account the limited facilities available in the DSP. An il-
lustrative example of the consequences of these constraints can be found in the fact that
the strong computational limits restrict the frequency resolution of the time/frequency
transforms which are necessary for those that make use of 'spectral information'. Thus,
the selection of an appropriate number of features becomes one of the key topics in-
volved in the successfully design of the classifier. This trade-off consists of reducing the
number of features while maintaining the probability of correct classification, and the
speech intelligibility perceived by the user. As illustrated in Figure 4, this is equivalent
to diminishing the dimension of a vector
F
composed by the selected features.
Classifying the audio signal entering the hearing aid as belonging to speech, music or
noise, requires the unit to extract (compute) features containing the relevant information
that should assist the classifier in distinguishing between the classes. For illustrative
purposes, we have grouped these two tasks into the so-called Functional Group B illus-
trated in Figure 3. It is necessary for classifying the input sound to carry out a number of
signal processing steps summarized in subsection 3.2, and illustrated in Figure 4.
3.2 Mathematical Characterization of the General Feature Extraction Process
The input audio signal to be classified,
X
(
t
), which will be assumed as a stochastic
process, is segmented into frames as follows:
Search WWH ::

Custom Search