Database Reference
In-Depth Information
Measure groups that contain measures with the
Distinct Count
aggregation type
require their own specific partitioning strategy. While you should still partition by
Time, you should also partition by non-overlapping ranges of values within the
column you're doing the distinct count on. A lot more detail on this is available
in the following white paper:
http://tinyurl.com/distinctcountoptimize
.
It's worth looking at the distribution of data over partitions for dimensions we're not
explicitly slicing by to see how well partition elimination will work for them. You
can see the distribution of member data IDs (the internal key values that Analysis
Services creates for all members on a hierarchy) for a partition by querying the
Discover_Partition_Dimension_Stat
DMV, for example:
SELECT *
FROM SystemRestrictSchema($system.Discover_Partition_Dimension_Stat
,DATABASE_NAME = 'Adventure Works DW 2008'
,CUBE_NAME = 'Adventure Works'
,MEASURE_GROUP_NAME = 'Internet Sales'
,PARTITION_NAME = 'Internet_Sales_2003')
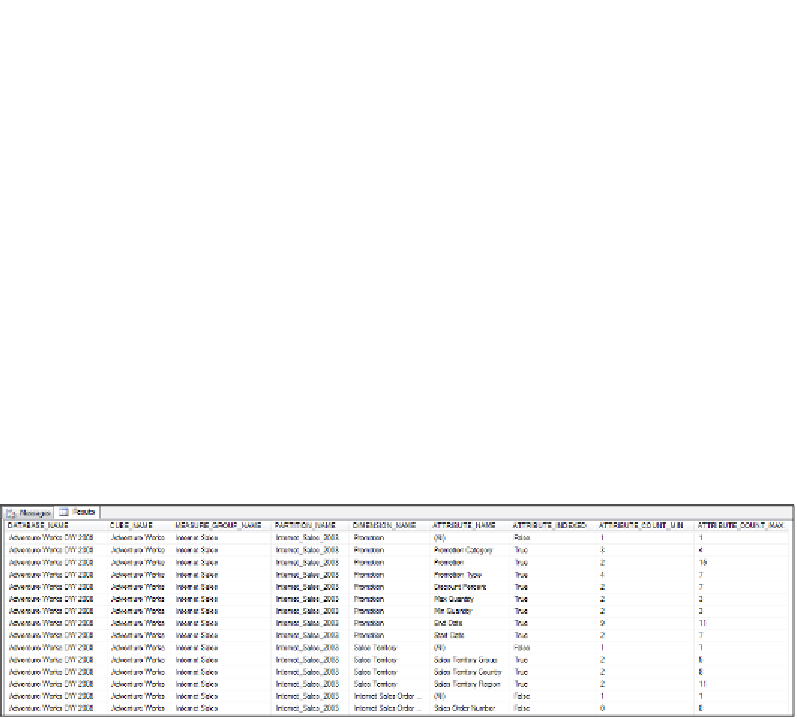
The following screenshot shows what the results of this query look like:
There's also a useful Analysis Services stored procedure that shows the
same data and any partition overlaps included in the Analysis Services Stored
Procedure Project (a free, community-developed set of sample Analysis Services
stored procedures):
http://tinyurl.com/partitionhealth
. This blog entry
describes how you can take this data and visualize it in a Reporting Services
report:
http://tinyurl.com/partitionslice
.

Search WWH ::

Custom Search