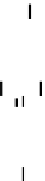Information Technology Reference
In-Depth Information
Output (
t
)
Output (
t-1
)
Output (
t-
T
)
Context (
t-
T
+1
)
[= Hidden (
t-
T
)]
Context (
t
)
[= Hidden (
t-1
)]
Hidden (
t
)
Context (
t-
T
)
Input (
t
)
[= Output (
t-1
)]
Input (
t-1
)
[= Output (
t-2
)]
Input (
t-
T
)
Parametric
Bias
Fig. 1. Network architecture.
The Elman-type Recurrent Neural Network with Parametric Bias
(RNNPB) unfolded in time. Dashed arrows indicate a verbatim copy of the activations (weight
connections set equal to 1.0). All other adjacent layers are fully connected.
t
is the current time
step,
T
denotes the length of the time series.
proportionally to the absolute mean value of prediction errors being backpropagated to
the
i
-th node over time
T
:
T
1
T
δ
PB
i,t
γ
i
∝
.
(3)
t
=1
The other adjustable weights of the network are updated via an adaptive mechanism,
inspired by the resilient propagation algorithm proposed by Riedmiller and Braun [10].
However, there are decisive differences. First, the learning rate of each neuron is ad-
justed after every epoch. Second, not the sign of the partial derivative of the corre-
sponding weight is used for changing its value, but instead the partial derivative itself
is taken.
To determine if the partial derivative of weight
w
ij
changes its sign we can compute:
ij
=
∂E
ij
∂E
ij
∂w
ij
(
t
)
∂w
ij
(
t
−
1)
·
(4)
If
ij
<
0
, the last update was too big and the local minimum has been missed. There-
fore, the learning rate
η
ij
has to be decreased by a factor
ξ
−
<
1
. On the other hand, a
positive derivative indicates that the learning rate can be increased by a factor
ξ
+
>
1
to speed up convergence. This update of the learning rate can be formalized as:
⎧
⎨
ξ
−
,η
min
)
if
ij
<
0
,
max
(
η
ij
(
t
−
1)
·
η
ij
(
t
)=
ξ
+
,η
max
)
if
ij
>
0
,
(5)
min
(
η
ij
(
t
−
1)
·
⎩
η
ij
(
t
−
1)
else.
The succeeding weight update
Δw
ij
then obeys the following rule:
Δw
ij
(
t
)=
−
Δw
ij
(
t
−
1)
if
ij
<
0
,
(6)
∂E
ij
η
ij
(
t
)
·
∂w
ij
(
t
)
else.