Database Reference
In-Depth Information
Precision
Recall
Schwellwert
Ahnlichkeitsmaß
Partitionsgroße
E
zienz
Abbildung 2.6: Zielkonflikt der Duplikaterkennung
70
zwar dasselbe Realwelt-Objekt, unterscheiden sich jedoch häufig in ihren Attribut-
ausprägungen, speziell bei Attributen die das Realwelt-Objekt identifizieren. Das
Prinzip der Duplikaterkennung ist der paarweise Vergleich. Hierfür wird domä-
nenspezifisches Wissen benötigt, um geeignete Ähnlichkeitsmaße zu definieren.
Die Ursachen für Duplikate sind vielfältig. Bei der Integration mehrerer Sys-
teme wurden die Daten ggf. mehrfach erfasst. In einem einzigen Datenbestand
entstehen Duplikate häufig durch eine fehlerhafte Erfassung, beispielsweise durch
Tipp- oder Hörfehler, Verwendung unterschiedlicher Schreibweisen oder Messfeh-
ler. Weitere Gründe für die Entstehung von Duplikaten sind die Alterung und die
Transformation von Daten. Durch Duplikate wird unnötig Platz und Rechenleis-
tung verbraucht. Es ist nicht mehr möglich, durch einfaches Zählen die Anzahl der
Realwelt-Objekte zu identifizieren, und bei Änderungs- und Lösch-Operationen
entstehen Inkonsistenzen, da nicht alle Elemente erfasst werden. Aus wirtschaftli-
cher Sicht bedeuten Duplikate, dass Kunden ggf. mehrfach angeschrieben werden,
wodurch ein Imageschaden entsteht, oder Mengenrabatte ungenutzt bleiben.
Die Duplikaterkennung erfolgt in fünf Schritten. Ziel der
Vorverarbeitung
ist
es, die Daten zu vereinheitlichen und offensichtliche Fehler zu korrigieren. Dies
umfasst eine Vereinheitlichung der Groß- und Kleinschreibung, Beseitigung von
Tippfehlern, Ersetzen bekannter Abkürzungen, Vereinheitlichung von Namen und
Adressen, Transformation von Formaten, Konvertierung von Einheiten und Be-
handlung von fehlenden Werten. Nach der Vorverarbeitung erfolgt eine
Reduzie-
rung des Suchraums
. Dies ist notwendig, da der Aufwand eines vollständigen paar-
weisen Tupelvergleichs quadratisch ist und daher insbesondere bei großen Daten-
beständen zu hohen Kosten führt. Zwei Verfahren zur Reduzierung des Suchraums
sind das Blocking, welches die Datenmenge in disjunkte Blöcke unterteilt und die
Sorted-Neighborhood-Methode, welche ein Fenster fixer Größe über die sortier-
70
Quelle: [19], S. 334




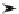










Search WWH ::

Custom Search