Information Technology Reference
In-Depth Information
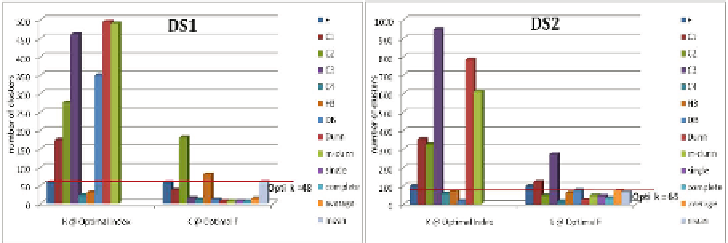
Fig. 16.7.
Indices ability to identify the optimal number of clusters - application on
DS1 and DS2 for document clustering
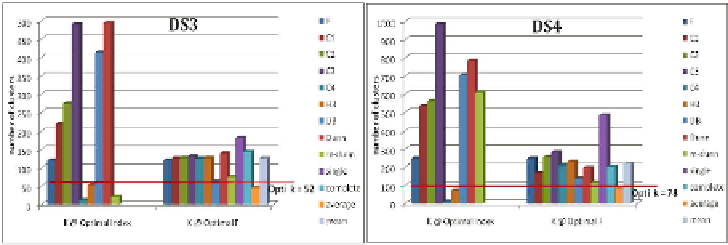
Fig. 16.8.
Indices ability to identify the optimal number of clusters - application on
DS3 and DS4 for word clusterin
On involving indices as criterion functions.
Next, we compare the ability
of validity indices - when involved as criterion functions - to drive an algorithm
toward “optimal” partitions. That is, by looking at Figures 16.5, 16.6 (
“Optimal
F”
), we can conclude that the
H
3and
C
3 indices could lead the agglomera-
tive algorithm to the optimal partitions in terms of
FScore
in all our datasets.
For document clustering, the
H
3 index could lead to an
FScore
of 0.695 and
0.592 respectively in DS1 and DS2. These are interesting rates since they are
somehow comparable to the “upper-bound” rates reached when involving the
FScore
index itself as criterion function. On the other hand, for word cluster-
ing, much lower
FScores
were noticed in DS3 and DS4. That is, a maximal
FScore
of only 0.245 was attained when using the
H
3 index. This wide gap in
FScore
values between both applications, i.e., word and document clustering, is
certainly due to the relatively poor representation of words patterns. We argue
that representing documents by their content terms is much more meaningful for
similarity calculations than representing words by their context words. This is
what makes word clustering look like a hard tasks, comparing to other clustering
applications.