Information Technology Reference
In-Depth Information
Finally, this experiment shows that
IBM_OPT
(respectively
IBM2_OPT
) outperform
IBM
(respectively
IBM2
). The performance gain (materialized by the gap between the
corresponding curves) remains constant. Indeed, this difference corresponds to the
saved time of the data structure construction and it is independent of the support
threshold. For the dataset composed of 300,000 sequences, we observe the same
behavior than in the previous experiment (Fig. 8.7). The size of
SV
is about 219 with
50,000 distinct sequences in the dataset and the structure is generated in 7.5 seconds.
For a dataset composed of 600,000 sequences (Fig. 8.8),
SPAM
algorithm produced a
memory overflow and failed. The size of
SV
is composed of 265 items with 90,000
distinct sequences in the dataset and the time to generate the structure is about 22.6
seconds. We observe that
PrefixSPAN
shows better performances than
IBM.
IBM_OPT
and
IBM2_OPT
still outperform
PrefixSPAN
.
IBM2
remains better than
IBM
and than
PrefixSPAN,
especially for a support bellow 0.3.
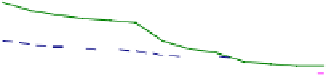
For a dataset composed of 1,000,000 sequences, the size of
SV
is about 370 with
160,000 distinct sequences in the dataset and the time to generate the structure is
about 80 seconds.
PrefixSPAN
consolidates its performance compared to
IBM
.
IBM_OPT
always outperforms
PrefixSPAN
. In general,
IBM
shows better
performances than
PrefixSPAN
, unless the support is high. Conversely,
IBM_OPT
outperforms
PrefixSPAN
when the support is greater than 0.1. In order to measure the
impact of the alphabet size on the performances, we have generated datasets using a
larger alphabet (i.e. with more than 20 distinct items). Fig.. 8.10 and 8.11 show the
results for 20 and 35 distinct items for dataset composed of respectively 130,000 and
100,000 sequences. For 20 distinct items,
SV
is composed of 192 items with 26,000
distinct sequences in the dataset. For the dataset composed of 35 distinct items,
SV
is
composed of 214 items with 32,000 distinct sequences. We observe that
PrefixSPAN
outperforms
IBM_OPT
and IBM, but
IBM
and
IBM_OPT
win
PrefixSPAN
. Until 35
distinct items,
IBM_OPT
wins
PrefixSPAN
, with a support lower than 0.2. But,
PrefixSPAN
outperforms
IBM
due to the generation of the structure.
1,000,000
700
IB M2 _ Op t
IB M_ Op t
Pr e f i x Span
IB M2
IB M
600
500
400
300
200
100
0
Support
Fig. 8.9.
Performances with 1,000,000 rows