Information Technology Reference
In-Depth Information
mobility for the reported population. For instance: (Home, Leisure, Home) is the most
frequent with a support of 49%; (Home, Work, Home) is surprisingly less frequent
with 37%, among which 9% correspond to (Home, Work, Home, Work, Home);
(Home, School, Leisure, Home) appears in 11% of the sequences; while (Home,
Shopping, Home, Leisure, Home) appears in 8% of them.
As for the scalability test, we generated and tested three different sizes of datasets
with respectively: 100,000; 300,000; 600,000; and 1,000,000 rows. Items and the size
of the sequences have been randomly generated for most experiments. The size of
sequences was randomly generated from 2 to 60, and the number of distinct items was
about 10 (from 0 to 9). This number has been pushed to 20, 35 and 75 distinct items,
notably by using the public dataset from UCI KDD archive. For our experimentations,
we have used the packages PrefixSPAN-0.4.tar.gz
2
and Spam.1.3.1.tar.gz
3
. Moreover,
we have augmented the activity dataset by randomly generating arbitrary sequences.
Finally, we have used the public datasets provided in UCI KDD archive chess.dat
4
that has a larger alphabet than in the activity survey dataset. We have measured two
features: the overall response time from one hand, and the storage cost from the other.
Moreover, we have studied two variants of the IBM algorithm at the implementa-
tion level. The first one, called IBM2, is based on the observation that the binary
matrix manipulation necessitates shifting operations. In order to avoid these superflu-
ous and costly computations, we have proposed the variant algorithm IBM2 where the
Bitmap is replaced by a matrix of Boolean types. This type takes 8 bits in languages
like Java or C++. This solution requires more space in memory, but it performs better
since accessing each cell becomes direct. The gain in performances of IBM2 has been
confirmed by experimental results bellow. The second variant, called
IBM_OPT
(respectively
IBM2_OPT
when combined with
IBM2
),
uses the fact that the structure
of IBM in independent from the support threshold value. The idea is to serialize it as a
Java object
and stored in a file, which makes it available for later use after a simple
load in the main memory. Thus the cost of pre-processing can be totally
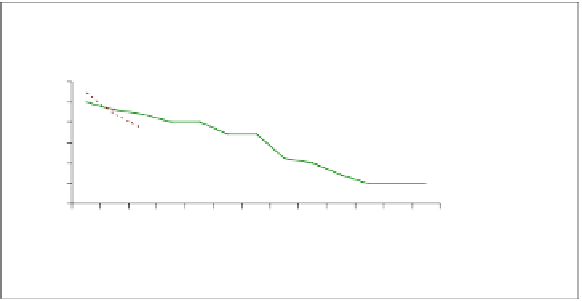
100,000
30
25
PrefixSpan
IB M
IB M_Opt
IB M2
IBM2_Opt
SPAM
20
15
10
5
0
Support
Fig. 8.6.
Performances with 100,000 rows
2
http://chasen.org/~taku/software/
PrefixSPAN
/
3
http://himalaya-tools.sourceforge.net/Spam/#download
4
http://kdd.ics.uci.edu