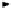Information Technology Reference
In-Depth Information
renewing
data weight
5 times
decision tree
generation
with entoropy
+information ratio
generating valudation
and training datasets
with random split
voting with
weighting based
on error rate
apportionment of
credit
END
START
20 times
or low target
modifying classifiers
with synthesising
rules
deleting weak
classifiers
5 times
Fig. 6.3.
The learning algorithm constructed by CAMLET for the dataset of the
meningitis data mining result
Table 6.3.
Accuracies (%), Recalls (%), and Precisions (%) of the five learning
algorithms
Evaluation on the training dataset
Learning
Algorithms
Recall
Precision
Acc.
I
NI
NU
I
NI
NU
CAMLET
89.4
70.8
97.9
11.1
85.0
90.2
100.0
Stacking
81.1
37.5
96.3
0.0
72.0
87.0
0.0
Boosted J4.8
99.2
97.9
99.5
100.0
97.9
99.5
100.0
Bagged J4.8
87.3
62.5
97.9
0.0
81.1
88.4
0.0
J4.8
85.7
41.7
97.9
66.7
80.0
86.3
85.7
BPNN
86.9
81.3
89.8
55.6
65.0
94.9
71.4
SVM
81.6
35.4
97.3
0.0
68.0
83.5
0.0
CLR
82.8
41.7
97.3
0.0
71.4
84.3
0.0
OneR
82.0
56.3
92.5
0.0
57.4
87.8
0.0
Leave
.
One-Out(LOO)
Learning
Algorithms
Recall
Precision
Acc.
I
NI
NU
I
NI
NU
CAMLET
80.3
7.4
73.0
0.0
7.4
73.0
0.0
Stacking
81.1
37.5
96.3
0.0
72.0
87.0
0.0
Boosted J4.8
74.2
37.5
87.2
0.0
39.1
84.0
0.0
Bagged J4.8
77.9
31.3
93.6
0.0
50.0
81.8
0.0
J4.8
79.1
29.2
95.7
0.0
63.6
82.5
0.0
BPNN
77.5
39.6
90.9
0.0
50.0
85.9
0.0
SVM
81.6
35.4
97.3
0.0
68.0
83.5
0.0
CLR
80.3
35.4
95.7
0.0
60.7
82.9
0.0
OneR
75.8
27.1
92.0
0.0
37.1
82.3
0.0
The results of the performances of the five learning algorithms for the entire
training dataset and the results of Leave-One-Out are shown in Table 6.3. All
the Accuracies, Recalls of I and NI, and Precisions of I and NI are higher than
those of the predicting majority labels.
As compared to the accuracy of OneR, the other learning algorithms achieve
equal or higher performances using combinations of multiple objective indices,
rather than by sorting with a single objective index. With regard to the Recall
values for class I, BPNN achieved the highest performance. The other algorithms
exhibit lower performance than OneR, because they tended to learn classification
patterns for the majority class NI.
The accuracy of Leave-One-Out demonstrates the robustness of each learning
algorithm. The Accuracy (%) of these learning algorithms ranged from 75.8% to
81.9%. However, these learning algorithms were not able to classify the instances
of class NU, because it is dicult to predict a minor class label in this dataset.
The learning algorithm constructed by CAMLET showed the second high-
est accuracy for the entire training dataset, compared with the other learning