Database Reference
In-Depth Information
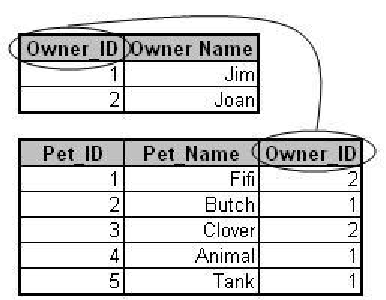
Figure 2-2: A simple database with a relation between two tables.
Figure 2-2 depicts a relational database environment with two tables. The first table contains
information about pet owners; the second, information about pets. The tables are related by the
single column they have in common: Owner_ID. By relating tables to one another, we can reduce
redundancy of data and improve database performance. The process of breaking tables apart and
thereby reducing data redundancy is called
normalization
.
Most relational databases which are designed to handle a high number of reads and writes (updates
and retrievals of information) are referred to as
OLTP (online transaction processing)
systems.
OLTP systems are very efficient for high volume activities such as cashiering, where many items
are being recorded via bar code scanners in a very short period of time. However, using OLTP
databases for analysis is generally not very efficient, because in order to retrieve data from multiple
tables at the same time, a query containing joins must be written. A
query
is simple a method of
retrieving data from database tables for viewing. Queries are usually written in a language called
SQL (Structured Query Language; pronounced 'sequel').
Because it is not very useful to only
query pet names or owner names, for example, we must
join
two or more tables together in order
to retrieve both pets and owners at the same time. Joining requires that the computer match the
Owner_ID column in the Owners table to the Owner_ID column in the Pets table. When tables
contain thousands or even millions of rows of data, this matching process can be very intensive
and time consuming on even the most robust computers.
For
much
more
on
database
design
and
management,
check
out
geekgirls.com:
(
http://www.geekgirls.com/ menu_databases.htm
).