Database Reference
In-Depth Information
1)
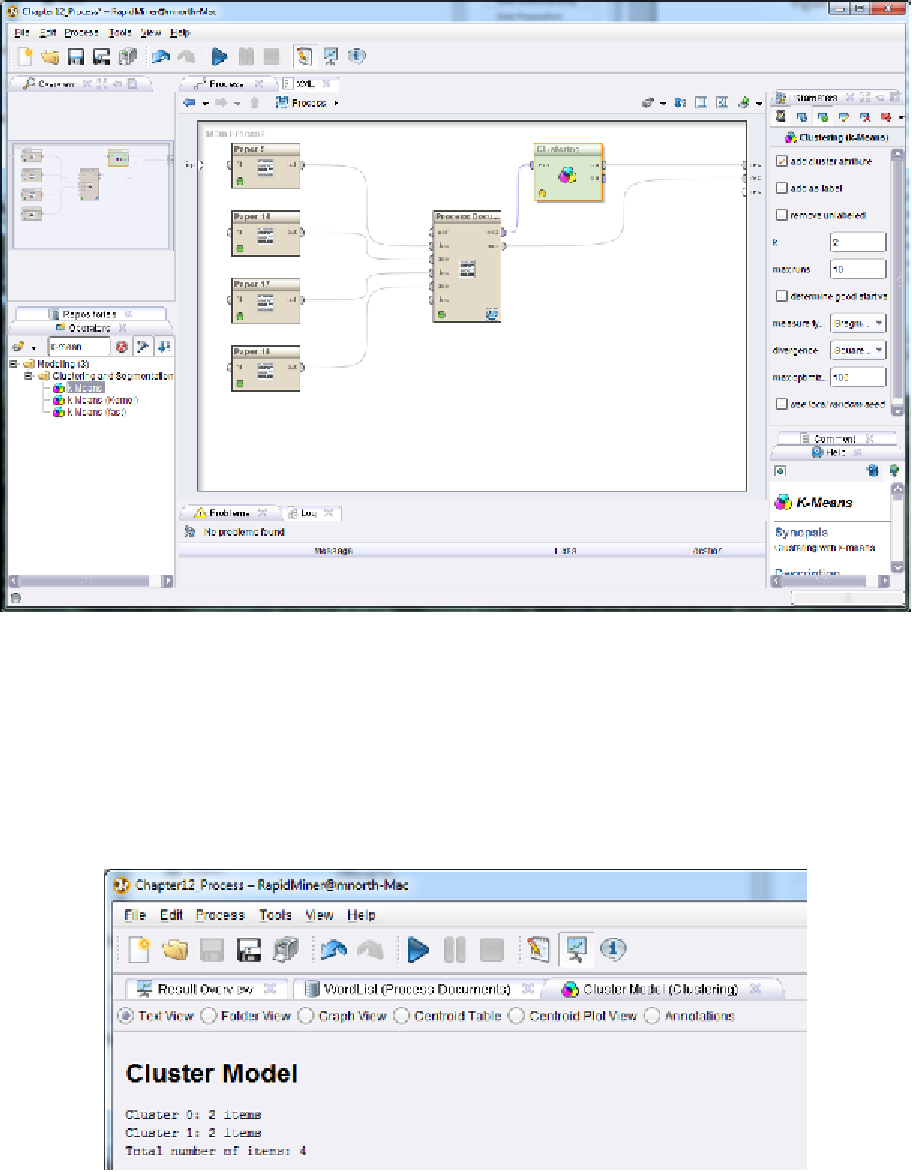
Switch back to design perspective. Locate the k-Means operator and drop it into your
stream between the
exa
port on Process Documents and the
res
port (Figure 12-19).
Figure 12-19. Clustering our documents using their token frequncies as means.
2)
For this model we will accept the default
k
of 2, since we want to group Hamilton's and
Madison's writings together, and keep Jay's separate. We'd hope to get a
Hamilton/Madison cluster, with paper 18 in that one, and a Jay cluster with only his paper
in there. Run the model and then click on the Cluster Model tab.
Figure 12-20. Cluster results for our four text documents.