Database Reference
In-Depth Information
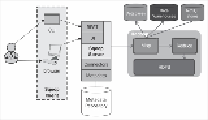
tem for efficiently transferring bulk data between Hadoop and structured databases.
Sqoop is used for loading or unloading data from database/data warehouse, and
NOSQL stores into HDFS. It comes with a connector-based architecture, where it
can support multiple plugins. Have a look at the following figure:
The following example demonstrates a
sqoop
command to import data from a data
store using JDBC connector into Hive tables (more on Hive is covered in the next
sections of this chapter).
sqoop import \
--connect jdbc:<<pjdbc connectors>> \
--username <<name>> \
--password <<password>> \
--table <<hive-table-name>> \
--hive-import
The advantage with Sqoop is that, it automatically creates the metadata for the Hive
table. In the case where the Hive table does not exist, it creates the same.
To learn more on Apache Sqoop refer
http://sqoop.apache.org/docs/1.99.2/Buildin-
Greenplum BulkLoader for Hadoop
As a part of the HD distribution, Greenplum ships data loader components to help
bulk load large volumes of data into HDFS. This section again introduces readers to
bulk loader options in Greenplum for HD but is not intended to serve as a tutorial.
Greenplum Data Loader is a batch data-loading tool that leverages the GPHD
MapReduce framework. Greenplum Data Loader manages a cluster of machines
that support multijob/multiuser, parallel data loading, and optimizes disk/network
bandwidth for best possible throughput.
Search WWH ::

Custom Search