Information Technology Reference
In-Depth Information
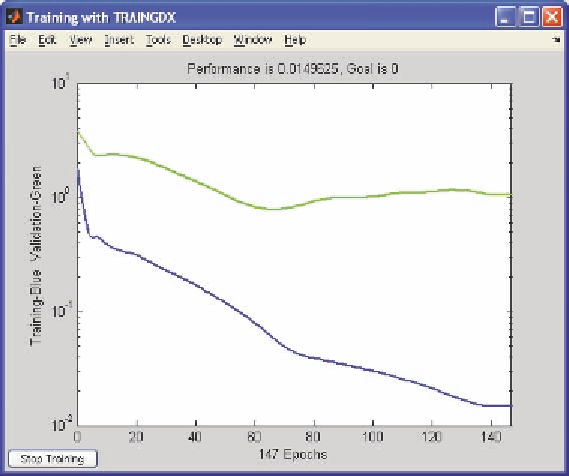
Figure 10. Example neural network training and cross-validation errors
presented is currently at about epoch 145, and we can see that the cross-validation set error was at its
lowest point at around epoch 65. Therefore, because the cross-validation set error increases after that,
this suggests that the neural network is presumably overfitting.
In addition to testing the backpropagation-learning algorithm with cross-validation early stopping,
we also used a faster training algorithms as well as an attempt to improve the generalization of the
model. In particular, we used the Levenberg-Marquardt algorithm (Marquardt, 1963) as applied to Neu-
ral Networks (Hagan et al., 1996; Hagan & Menhaj, 1994). This algorithm is one of the fastest training
algorithms available with training being 10-100 times faster than simple gradient descent backpropaga-
tion of error (Hagan & Menhaj, 1994).
The Levenberg-Marquardt neural network-training algorithm is further combined into a framework
that permits estimation of the network's generalization by the use of a regularization parameter. Neural
Network performance measures typically measure the error of the outputs of the network, such as the
mean squared error (MSE). However, a regularization performance function which includes the sum
of the weights and biases can be used instead, combined with a regularization parameter, which deter-
mines how much weight is given to the sum of weights and bias in the formula (MSEREG = γ MSE +
(1 - γ) MSW). This regularization parameter permits the control of the ratio of impact between reducing
the error of the network and the number of weights or power of the network such that one can be less
concerned with the size of the neural network and control the effective power of it directly by the use
of this parameter.
The tuning of this regularization parameter is automated within the Bayesian framework (MacKay,
1992) and, when combined with the Levenberg-Marquardt training algorithm, results in high performance
training combined with a preservation of generalization by avoiding overfitting of the training data
Search WWH ::

Custom Search