Information Technology Reference
In-Depth Information
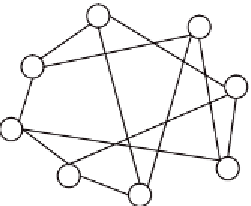
Figure 2. The initial all-k-nearest-neighbor (Aknn) graph G
0
with n nodes (n=8 in this case). Each node
in this graph contains a single Web page (e.g., node v
1
contains Web page d
1
) and is connected to its
k-nearest neighbors (k is 3 in this case). The edge connecting two nodes is weighted by the similarity
between the two nodes.
v
1
={d
1
}
v
8
={d
8
}
v
2
={d
2
}
v
7
={d
7
}
sim(v
2
,v
3
)
v
3
={d
3
}
v
6
={d
6
}
v
5
={d
5
}
v
4
={d
4
}
Generating an Initial Sparse Graph
In this subsection we describe how to arrange a set of Web pages to form a weighted graph (e.g., Figure
2) based on the similarities of Web pages. A Web page is first converted to a vector of terms:
d
i
= (w
i1
, …, w
ij,
…, w
im
)
(11)
where Web page
d
i
has
m
terms (also called features), and the weights of the features are indexed from
w
i1
to
w
im
. Usually a feature consists of one to three words, and its weight is the number of occurrences of
the feature in a Web page. Common methods to determine
w
ij
are the term frequency-inverse document
frequency (tf-idf) method (Salton & Buckley, 1988) or the structure-oriented term weighting method
(Peng, 2002; Riboni, 2002). Many approaches (e.g., Rijsbergen, 1979; Strehl et al., 2000) are then used
to measure the similarity between two Web pages by comparing their vectors. We choose the cosine
(Rijsbergen, 1979) as the metric for measuring the similarity, i.e.,
cos
(
d
i
, d
j
) is the cosine similarity
between Web pages
d
i
and
d
j
. We then define the similarity between two clusters
u
and
v
as:
∑
cos( , )
d d
i
j
d u d v
∈
,
∈
(12)
sim(u,v)
=
i
j
| || |
u v
where
d
i
is a Web page within cluster
u
,
d
j
is a Web page within cluster
v
,
|u|
is the number of Web pages
in cluster
u
.
An initial sparse graph is generated by using the
sim(u, v)
to weight the edge between two nodes
u
and
v
. Figure 2 shows an example. Initially each node in the graph contains only one Web page. Each
node does not connected to all other nodes, but only to
k
most similar nodes. By choosing
k
small in
comparison to the total number of nodes, we can reduce the computation time in later clustering pro-
cesses.
Bottom-Up Cluster-Merging Phase
In the bottom-up cluster-merging phase we aim at maximizing the intra-similarities of clusters by merg-
ing the most similar clusters together (see Figure 3 for example). To achieve this goal, we transform the
Search WWH ::

Custom Search