Database Reference
In-Depth Information
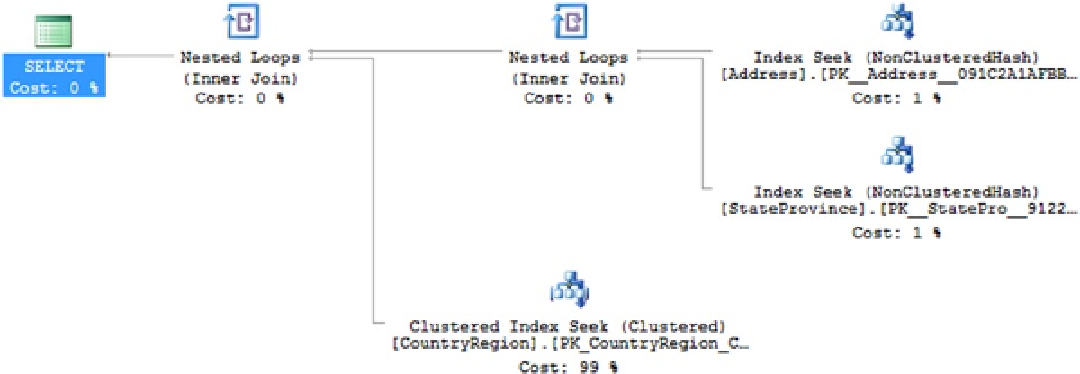
With the data loaded, the following query returns a single row and has an execution plan that looks like Figure
23-2
:
SELECT a.AddressLine1,
a.City,
a.PostalCode,
sp.Name AS StateProvinceName,
cr.Name AS CountryName
FROM dbo.Address AS a
JOIN dbo.StateProvince AS sp
ON sp.StateProvinceID = a.StateProvinceID
JOIN dbo.CountryRegion cr
ON cr.CountryRegionCode = sp.CountryRegionCode
WHERE a.AddressID = 42;
Figure 23-2.
An execution plan showing both in-memory and standard tables
As you can see, it's entirely possible to get a normal execution plan even when using in-memory tables.
The operators are even the same. In this case, you have three different index seek operations. Two of them are against
the nonclustered hash indexes you created with the in-memory tables, and the other is a standard clustered index
seek against the standard table.
The principal performance enhancements come from the lack of locking and latching allowing massive inserts
and updates while simultaneously allowing for querying. But, the queries do run faster as well. The previous query
resulted in the following execution time and reads:
Table 'CountryRegion'. Scan count 0, logical reads 2
CPU time = 0 ms, elapsed time = 19 ms.
Running a similar query against the
AdventureWorks2012
database results in this behavior:
Table 'CountryRegion'. Scan count 0, logical reads 2
Table 'StateProvince'. Scan count 0, logical reads 2
Table 'Address'. Scan count 0, logical reads 2
CPU time = 0 ms, elapsed time = 154 ms.
While it's clear that the execution times are much better with the in-memory table, what's not clear is how the
reads are dealt with. But, since I'm talking about reading from the in-memory storage and not either pages in memory
or pages on the disk but the hash index instead, things are completely different in terms of measuring performance.