Database Reference
In-Depth Information
How did the optimizer arrive at a covering index for this query based on the index provided? It's aware that
on a table with a clustered index, the clustered index key, in this case the
BusinessEntitylD
column, is stored as a
pointer to the data with the nonclustered index. That means any query that incorporates a clustered index and a set
of columns from a nonclustered index as part of the filtering mechanisms of the query, the
WHERE
clause, or the join
criteria can take advantage of the covering index.
To see how these three different indexes are reflected in storage, you can look at the statistics of the indexes
themselves using
DBCC SHOWSTATISTICS
. When you run the following query against the index, you can see the output
in Figure
11-12
:
DBCC SHOW_STATISTICS('HumanResources.Employee',
AK_Employee_NationalIDNumber);
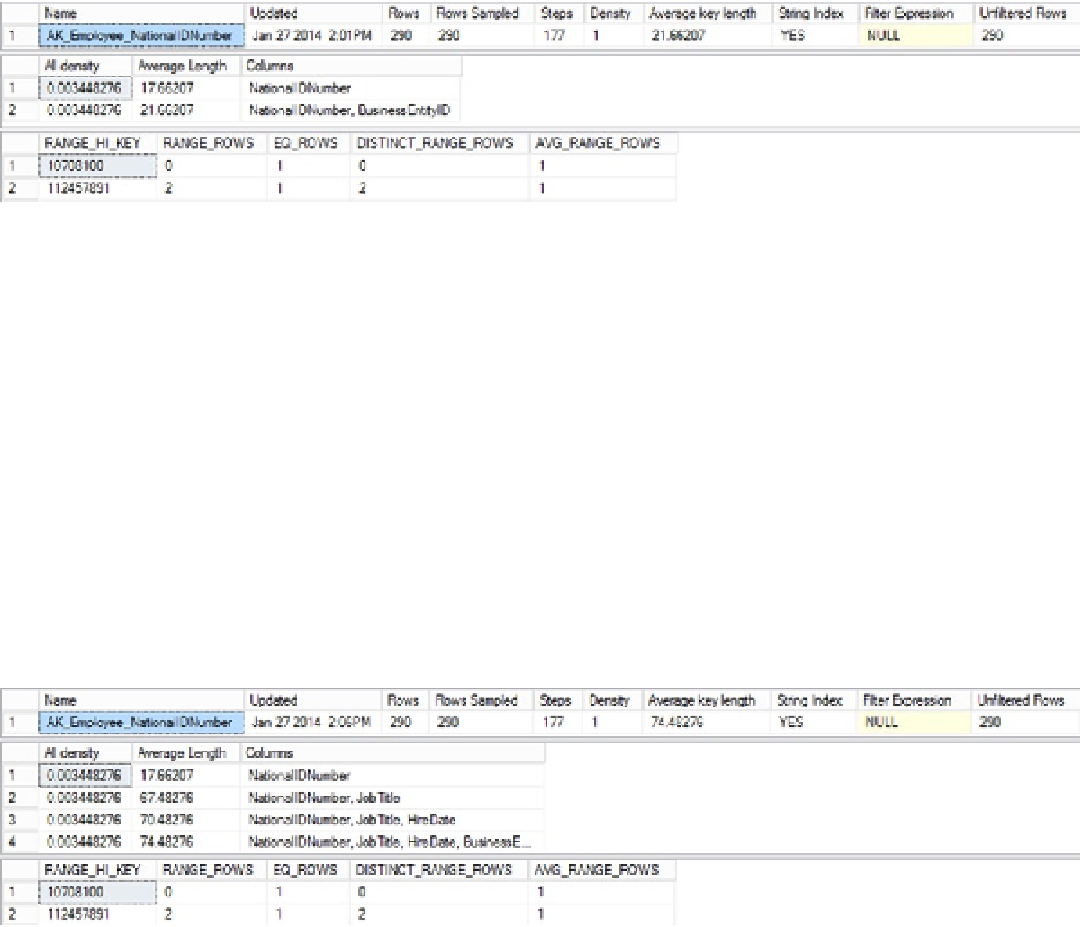
Figure 11-12.
DBCC SHOW_STATISTICS output for original index
As you can see, the
NationalIDNumber
is listed first, but the primary key for the table is included as part of the
index, so a second row that includes the
BusinessEntityID
column is there. It makes the average length of the key
about 22 bytes. This is how indexes that refer to the primary key values as well as the index key values can function as
covering indexes.
If you run the same
DBCC SHOW_STATISTICS
on the first alternate index you tried, with all three columns included
in the key, like so, you will see a different set of statistics (Figure
11-13
):
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON
[HumanResources].[Employee]
(NationalIDNumber ASC,
JobTitle ASC,
HireDate ASC )
WITH DROP_EXISTING ;
Figure 11-13.
DBCC SHOW_STATISTICS output for a wide key covering index