Database Reference
In-Depth Information
Covering Indexes
A
covering index
is a nonclustered index built upon all the columns required to satisfy a SQL query without going to
the heap or the clustered index. If a query encounters an index and does not need to refer to the underlying structures
at all, then the index can be considered a covering index.
For example, in the following
SELECT
statement, irrespective of where the columns are used within the statement,
all the columns (
StateProvinceld
and
PostalCode
) should be included in the nonclustered index to cover the
query fully:
SELECT a.PostalCode
FROM Person.Address AS a
WHERE a.StateProvinceID = 42;
Then all the required data for the query can be obtained from the nonclustered index page, without accessing the
data page. This helps SQL Server save logical and physical reads. If you run the query, you'll get the following I/O and
execution time as well as the execution plan in Figure
9-1
.
Table 'Address'. Scan count 1, logical reads 19
CPU time = 0 ms, elapsed time = 17 ms.
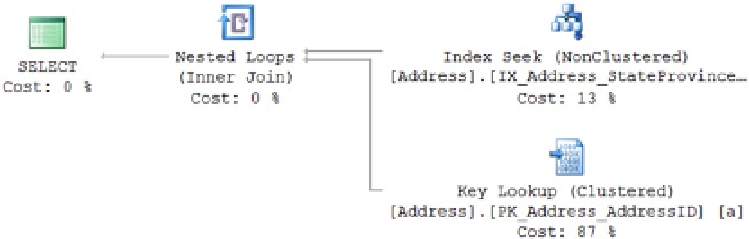
Figure 9-1.
Query without a covering index
Here you have a classic lookup with the
Key Lookup
operator pulling the
PostalCode
data from the clustered
index and joining it with the
Index Seek
operator against the
IX_Address_StateProvinceId
index.
Although you can re-create the index with both key columns, another way to make an index a covering index is
to use the new
INCLUDE
operator. This stores data with the index without changing the structure of the index itself.
Use the following to re-create the index:
CREATE NONCLUSTERED INDEX [IX_Address_StateProvinceID]
ON [Person].[Address] ([StateProvinceID] ASC)
INCLUDE (PostalCode)
WITH (
DROP_EXISTING = ON);
If you rerun the query, the execution plan (Figure
9-2
), I/O, and execution time change.
Table 'Address'. Scan count 1, logical reads 2
CPU time = 0 ms, elapsed time = 14 ms.