Database Reference
In-Depth Information
The clustered index is on the primary key, and although most access against the table may be through that key,
making the index useful, the clustered index in this instance is just not performing in the way you need. Although you
could expand the definition of the index to include all the other columns in the query, they're not really needed to
make the clustered index function, and they would interfere with the operation of the primary key. Instead, you can
use the
INCLUDE
operation to store the columns defined within it at the leaf level of the index. They don't affect the key
structure of the index in any way but provide the ability, through the sacrifice of some additional disk space, to make a
nonclustered index covering (covered in more detail later). In this instance, creating a different index is in order.
CREATE NONCLUSTERED INDEX ixTest
ON Sales.CreditCard (ExpMonth, ExpYear)
INCLUDE (CardNumber);
Now when the query is run again, this is the result:
Table 'CreditCard'. Scan count 1, logical reads 32
CPU time = 0 ms, elapsed time = 166 ms.
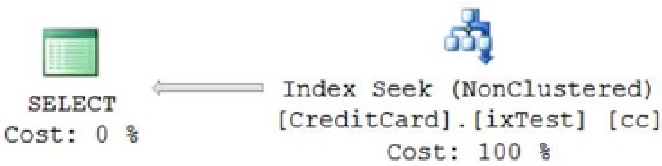
Figure
8-25
shows the corresponding execution plan.
Figure 8-25.
Execution plan with a nonclustered index
In this case, the
SELECT
statement doesn't include any column that requires a jump from the nonclustered index
page to the data page of the table, which is what usually makes a nonclustered index costlier than a clustered index for
a large result set and/or sorted output. This kind of nonclustered index is called a
covering index.
Clean up the index after the testing is done.
DROP INDEX Sales.CreditCard.ixTest;
Summary
In this chapter, you learned that indexing is an effective method for reducing the number of logical reads and disk I/O
for a query. Although an index may add overhead to action queries, even action queries such as
UPDATE
and
DELETE
can benefit from an index.
To decide the index key columns for a particular query, evaluate the
WHERE
clause and the join criteria of the
query. Factors such as column selectivity, width, data type, and column order are important in deciding the columns
in an index key. Since an index is mainly useful in retrieving a small number of rows, the selectivity of an indexed
column should be very high. It is important to note that nonclustered indexes contain the value of a clustered index
key as their row locator because this behavior greatly influences the selection of an index type.
In the next chapter, you will learn more about other functionality and other types of indexes available to help you
tune your queries.