Database Reference
In-Depth Information
Nested Loop Join
The final type of join I'll cover here is the nested loop join. For better performance, you should always strive to access
a limited number of rows from individual tables. To understand the effect of using a smaller result set, decrease the
join inputs in your query as follows:
SELECT pm.*
FROM Production.ProductModel pm
JOIN Production.ProductModelProductDescriptionCulture pmpd
ON pm.ProductModelID = pmpd.ProductModelID
WHERE pm.Name = 'HL Mountain Front Wheel';
Figure
7-11
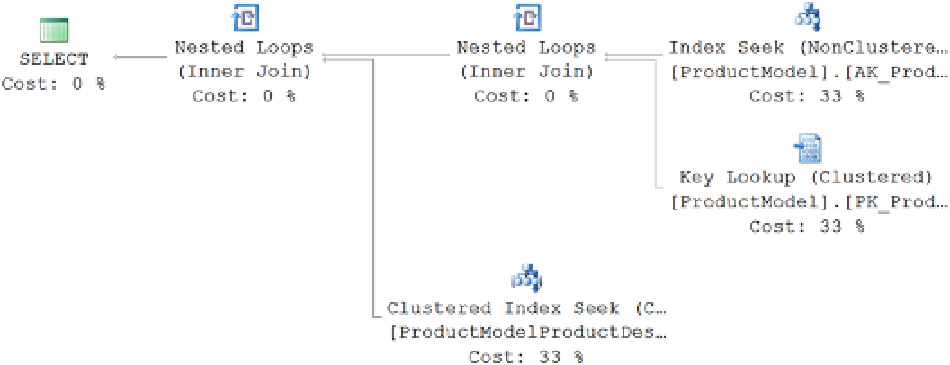
shows the resultant execution plan of the new query.
Figure 7-11.
Execution plan with a nested loop join
As you can see, the optimizer used a nested loop join between the two tables. It also added another nested loop
to perform the Key Lookup operation (I'll talk more about that in Chapter 6).
A nested loop join uses one join input as the outer input table and the other as the inner input table. The outer
input table is shown as the top input in the execution plan, and the inner input table is shown as the bottom input
table. The outer loop consumes the outer input table row by row. The inner loop, executed for each outer row,
searches for matching rows in the inner input table.
Nested loop joins are highly effective if the outer input is quite small and the inner input is larger but indexed.
In many simple queries affecting a small set of rows, nested loop joins are far superior to both hash and merge joins.
Joins operate by gaining speed through other sacrifices. A loop join can be fast because it uses memory to take a small
set of data and compare it quickly to a second set of data. A merge join similarly uses memory and a bit of
tempdb
to
do its ordered comparisons. A hash join uses memory and
tempdb
to build out the hash tables for the join. Although a
loop join can be faster at small data sets, it can slow down as the data sets get larger or there aren't indexes to support
the retrieval of the data. That's why SQL Server has different join mechanisms.
Even for small join inputs, such as in the previous query, it's important to have an index on the joining columns.
As you saw in the preceding execution plan, for a small set of rows, indexes on joining columns allow the query
optimizer to consider a nested loop join strategy. A missing index on the joining column of an input will force the
query optimizer to use a hash join instead.
Table
7-2
summarizes the use of the three join types.