Biomedical Engineering Reference
In-Depth Information
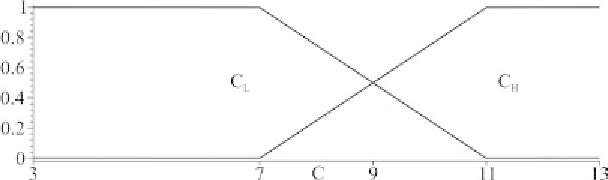
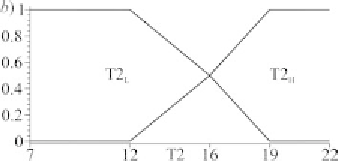
Figure 1. Fuzzification of C with two linguistic terms defined by two MFs (labeled CL and CH)
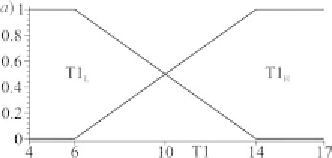
Figure 2. Fuzzification of condition attributes using two MFs
Table 2. Fuzzy data set using two MFs for each condition attribute
Object
T1 = [T1
L
, T1
H
]
T2 = [T2
L
, T2
H
]
T3 = [T3
L
, T3
H
]
C = [C
L
, C
H
]
u
1
[0.000,
1.000
]
[
0.625
, 0.375]
[0.000,
1.000
]
[
1.000
, 0.000]
u
2
[
0.500
,
0.500
]
[0.000,
1.000
]
[0.000,
1.000
]
[
0.750
, 0.250]
u
3
[
0.750
, 0.250]
[0.167,
0.833
]
[
0.625
, 0.375]
[
1.000
, 0.000]
u
4
[0.000,
1.000
]
[
1.000
, 0.000]
[
1.000
, 0.000]
[0.250,
0.750
]
A MF m(
x
) from the set describing a fuzzy
linguistic variable
Y
defined on
X
, can be viewed
as a possibility distribution of
Y
on
X
, that is
p(
x
) = m(
x
), for all
x
∈
X
the values taken by the
objects in
U
(also normalized so
∗
+
n
(see Zadeh, 1978). In
the limit, if
2
= 0, then
E
α
(
Y
) = 0, indicates no
ambiguity, whereas if
for
i
= 1, ..,
n
, and
1
=
0
n
= 1, then
E
α
(
Y
) = ln[
n
],
which indicates all values are fully possible for
Y
, representing the greatest ambiguity.
The ambiguity of attribute
A
(over the objects
u
1
, ..,
u
m
) is given as:
max
(
x
)
=
1
x
). The possibility measure
E
α
(
Y
) of ambiguity is
defined by
∈
X
n
1
m
∗
∗
+
E
α
(
Y
) =
g
(p) =
∑
(
−
)
ln[
i
]
,
E
α
(
A
) =
=
,
E
(
A
(
u
)
i
i
1
a
m
i
1
i
=
1
where
∗
= {
1
,
2
, …,
n
} is the permutation
of the normalized possibility distribution p =
{p(
x
1
),
p(
x
2
), …, p(
x
n
)}, sorted so that
∗
∗
∗
where
i
≥
∗
+1
∗
g
(
(
u
)
max
(
(
u
))
)
E
α
(
A
(
u
i
)) =
,
i
T
i
T
i
s
j
1
≤
j
≤
s





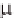
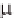








































Search WWH ::

Custom Search