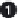Database Reference
In-Depth Information
>
"'http://api.nytimes.com/svc/search/v2/articlesearch.json?q=New+York+'"
\
>
"'Fashion+Week&begin_date={1}0101&end_date={1}1231&page={2}&api-key='"
\
>
"'<your-api-key>'"
:::
{
2009..2013
}
:::
{
0..99
}
> /dev/null
Computers / CPU cores / Max jobs to run
1:local / 4 / 1
Computer:jobs running/jobs completed/%of started jobs/Average seconds to
complete
local:1/9/100%
/0.4s
Basically, we're performing the same query for years 2009-2014. The API only allows
up to 100 pages (starting at 0) per query, so we're generating 100 numbers using brace
expansion. These numbers are used by the
page
parameter in the query. We're search‐
ing for articles in 2013 that contain the search term
New+York+Fashion+Week
. Because
the API has certain limits, we ensure that there's only one request at a time, with a
one-second delay between them. Make sure that you replace
<your-api-key>
with
your own API key for the article search endpoint.
Each request returns 10 articles, so that's 1000 articles in total. These are sorted by
page views, so this should give us a good estimate of the coverage. The results are in
JSON format, which we store in the
results
directory. The command-line tool
tree
(Baker, 2014) gives an overview of how the subdirectories are structured:
$
tree results | head
results
└── 1
├── 2009
│ └── 2
│ ├── 0
│ │ ├── stderr
│ │ └── stdout
│ ├── 1
│ │ ├── stderr
│ │ └── stdout
We can combine and process the results using
cat
(Granlund & Stallman, 2012),
jq
(Dolan, 2014), and
json2csv
(Czebotar, 2014):
$
cat results/1/*/2/*/stdout |
>
jq -c
'.response.docs[] | {date: .pub_date, type: .document_type, '
\
>
'title: .headline.main }'
| json2csv -p -k date,type,title > fashion.csv
Let's break down this command:
We combine the output of each of the 500
parallel
jobs (or API requests).
We use
jq
to extract the publication date, the document type, and the headline of
each article.