Biology Reference
In-Depth Information
Principal Component Analysis
Hierarchical Cluster Analysis
Scores (observations)
Loadings (variables)
t
2
p
2
t
1
p
1
PLS-Discriminant Analysis
Decision trees
Scores (observations)
Loadings (variables)
A
B
t
2
p
1
C
t
1
Variables
D
EF G
FIGURE 4
Data modeling workflow.
Principal Component Analysis
Principal component analysis (PCA) is
a bilinear factor model that is the most widely
used exploratory tool for unsupervised data anal-
ysis in metabolomics. It is well suited for dimen-
sionality reduction by taking advantage of
collinearity, as it summarizes multivariate data
tables in a low-dimensional subspace by a projec-
tion on orthonormal axes, the principal compo-
nents (PCs). The PCs aims at retaining the
largest variance from the original data matrix, in
a least squares sense.
73
PCA was
PC. Graphical displays allow assessing the distri-
bution of samples and variables, with the detec-
tion of natural groupings, trends, and outliers.
Additionally, subsequent analysis such as clus-
tering and classi
cation can be performed on the
scores of the observations instead of the original
variables. As metabolic phenomena are not
expected to be orthogonal, the rigid structure
imposed by orthogonal components may be
however detrimental to interpretation. In that
context, other methods such as independent
component analysis (ICA)
75
constitute relevant
alternatives to investigate metabolites.
76
Never-
theless, some limitations are inherent to the tech-
nique as
first formulated
by Pearson
74
to extract systematic variations in
multivariate data sets. This transformation of
the data into a new coordinate system, able to
grasp the salient characteristics of the data, is
very useful for simple display purposes. PCs are
linear combinations of the original variables,
and as they are orthogonal, the variability they
express is uncorrelated. The interpretation can
therefore be focused on a small number of
synthetic axes summarizing the variation within
the data set. PCA outputs are the scores
d
that is,
the coordinates of the observations in the new
PC subspace
d
and the loadings
d
that is, the
contributions of the individual variables to each
the number of
sources
(or
ICA
components) needs to be set
a priori
.
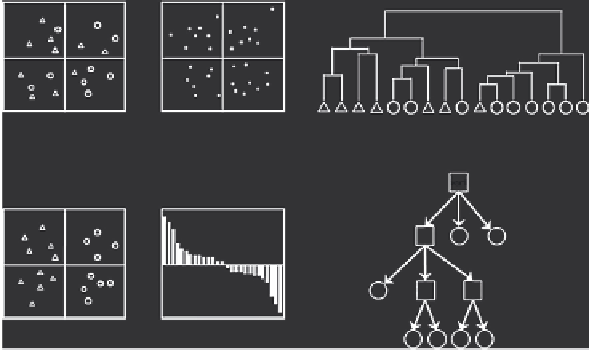
Cluster Analysis
Cluster analysis aims at the detection of
natural partitioning of objects. In other words,
it groups observations that are similar into
homogeneous subsets. These subclasses may
reveal patterns related to the phenomenon
under study. A distance function is used to
assess if the similarity between objects and
a wide variety of clustering algorithms based




Search WWH ::

Custom Search