Information Technology Reference
In-Depth Information
Table 22. The tuples for the eleven filters in Table 1.
Tuple
Filter
T
0,4
F
1
,F
2
T
1,1
F
3
T
1,2
F
4
T
2,2
F
5
T
3,2
F
6
,F
7
,F
8
,F
9
T
4,0
F
10
,F
11
Prefix Nodes
A: T
0,4
B: T
1,1
, T
1,2
C: T
2,2
D: T
3,2
E: T
4,0
F: T
3,2
G: T
3,2
H: T
4,0
Prefix Nodes
A: T
4,0
B: T
3,2
C: T
0,4
D: T
1,2
, T
3,2
E: T
0,4
F: T
1,1
G: T
2,2
, T
3,2
A
A
B
F
B
D
G
C
D
F
G
C
E
E
H
(a) The prefix trie of
f
1
(b) The prefix trie of
f
2
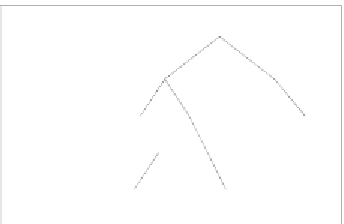
Figure 5. Two prefix tries with the tuple list in the prefix nodes.
there exists at least one packet matched to
F
a
and
F
b
simultaneously while there also exists
at least one other packet which only matches to
F
a
or
F
b
. In the last case,
F
a
is a subset of
F
b
if all packets matched to
F
a
also match to
F
b
. In this case, prefix
f
i
of
F
b
must be equal
to
f
i
or a sub-prefix of
f
i
of
F
a
for all
i
, where
1 ≤ i ≤ d
and
f
i
is the
i
th
prefix.
We use the third geometric relation that one filter is a subset of another filter to optimize
the search procedure of
PTSS
. We start the search procedure from the hash table of the filters
with longer prefixes. If there exists a matching filter, all the hash tables whose prefix lengths
are shorter than or equal to those of the matching hash table can be pruned to reduce the
number of hash tables to be accessed.
We illustrate our idea by using a set of 11 two-field filters in Table 1 as an exam-
ple. We list
six
tuples in Table 22. Figure 5 shows the prefix tries of both fields, where
each prefix node has a unique identifier corresponding to a tuple list. For an incoming
packet with the header specification (0001,0110), the best matching tuple list of
f
1
includes
T
0,4
,T
1,1
,T
1,2
,T
2,2
and
T
3,2
and that of
f
2
includes
T
4,0
,T
1,2
and
T
3,2
. By intersecting
both tuple lists,
PTSS
probes
T
1,2
and
T
3,2
for possible matching filters. With our scheme,
we can avoid probing
T
1,2
since a matching filter
F
6
is derived from
T
3,2
. Because
F
6
is a
subset of
F
4
, we store the action of
F
4
in
F
6
to ensure the accuracy of our scheme.
Next, we describe two construction procedures and the required data structure of our
scheme. The first procedure sorts the tuples according to their prefix length combinations.