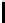Information Technology Reference
In-Depth Information
P
are updated and the fourth and fifth steps are repeated until the storage threshold can be
satisfied.
We use the filters in Table 1 as an example to illustrate our procedure of filter catego-
rization. We assume that
S
threshold
equals 16. Table 15 lists three iterations that calculate
the resulted storage of bit vectors. Initially, the value of
N
is 11 and that of
P
is 15. There-
fore,
S
is equal to 165 bits. In the first iteration, selecting the filters from
T
3,2
would result
in the minimum storage requirement. Therefore, the values of
N
and
P
are updated to 7
and 11, respectively. Since the filters of
T
3,2
have been selected in this iteration, they are
not considered in the subsequent iterations. In the second iteration, both tuples,
T
0,4
and
T
4,0
, result in the same storage requirement. In this case, we randomly choose
T
4,0
and
update the values of
N
and
P
. The procedure stops after the third iteration which results in
a storage requirement of 15 bits by selecting
T
0,4
. As a result, there are three tuples with
eight filters in the resulted tuple space. The remaining three filters are stored in the form of
bit vectors.
Table 15. Three Iterations of Our Filter Categorization Procedure for the Filters in
Table 1.
Initiation
First Iteration
Second Iteration
Third Iteration
N
T
i
P
T
i
Tuple
Filters
N −
N
T
i
P −
P
T
i
N −
N
T
i
P −
P
T
i
N −
N
T
i
P −
P
T
i
T
0
,
4
R
1
,R
2
2
3
9
12
5
8
3
5
T
1
,
1
R
3
1
1
10
14
6
10
4
7
T
1
,
2
R
4
1
0
10
15
6
11
4
8
T
2
,
2
R
5
1
1
10
14
6
10
4
7
T
3
,
2
R
6
∼ R
9
4
4
7
11
NA
NA
NA
NA
T
4
,
0
R
10
,R
11
2
3
9
12
5
8
NA
NA
We note that the calculation of
S
T
i
might underestimate the required storage of
T
i
.
While the filters of several tuples are selected for tuple space search, the prefix specifications
of the remaining filters which are originally not unique might become unique. Therefore,
in practice, the storage performance might be better than the estimated one. In the previous
example, the calculation for the tuple
T
1,2
in the third iteration is inexact since the value of
P − P
T
i
should be
seven
, rather than
eight
in Table 15. Although an accurate calculation
could be achieved, we believe that such overestimation of storage requirement may not
significantly affect the result of filter categorization. The main reason is due to the uneven
filter distribution in the existing filter databases. Most filters are distributed among few
tuples. Since these tuples are likely to be selected in the first few iterations, the calculation
for the remaining tuples is less important. Moreover, the extra computation for a more
precise calculation is costly and may not be feasible in practice.
To initiate the procedure of filter categorization, we construct
d
prefix tries and derive
necessary values by traversing these tries. In each following iteration, we simply compare
the cost of each tuple. Therefore, the time complexity of filter categorization is O(
dNW
).
After finishing the procedure of filter categorization, each filter must be stored in one of the
data structures, bit vectors or hash tables. Their storage locations are not changed unless
both data structures are reconstructed.