Information Technology Reference
In-Depth Information
algorithm can be stored in either a direct access array or a hash table, depending on the sizes
of data structures. We also provide the performance of our algorithm using prefix length
tuples (PLTs) and nested level tuples (NLTs) for a better illustration of their differences.
Since our scheme must perform one-dimensional searches, we adopt multiway search tree
[32] for one-dimensional search in our experiments. Our main reason for choosing this data
structure is its scalability with respect to the number of prefixes and prefix lengths.
3.5.1.
Trade-off Between the Number of Tuples and the Sizes of Cross-Product Ta-
bles
We start the performance evaluation by presenting the trade-off between the number of
tuples and the sizes of cross-product tables. We did this evaluation on three real filter
databases that are publicly available in [30]. For each database, we repeat the procedure
of tuple selection until we cannot create any cross-product tables. Therefore, we would
generate multiple cross-product tables. For each filter database, we also show the influence
of cross-product table size by adjusting the value of
C
threshold
.
We use three different
values of
C
threshold
, 64K, 256K and 1024K.
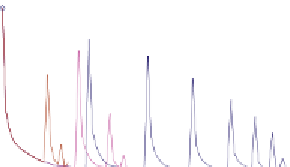
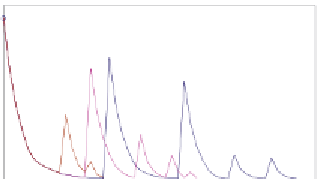
As shown Fig. 1
∼
3, the number of cross-product entries varies from several millions
to about half billion initially. With our algorithm, the number of cross-product entries is
decreased by removing the filters of selected tuples from the cross-product table. The pro-
cedure of tuple selection usually reduces the most cross-product entries in the first few
iterations. After generating a cross-product table whose size is less than
C
threshold
,we
start another round of tuple selection by moving all filters from tuple space to a new cross-
product table. Therefore, the number of cross-product entries raises again, and the proce-
dure of tuple selection repeats until cross-product tables with less than
C
threshold
entries are
generated. Our experimental results show that the number of cross-product tables usually
ties to the number of filters. Since IPC1 has the most filters, it also requires more iterations
of tuple selection and results in more cross-product tables than the other databases. In ad-
dition, our algorithm based on NLTs requires much less iterations than that based on PLTs
for ACL1 and IPC1, but slightly more than that based on PLTs for FW1. Therefore, using
NLTs in our algorithm could shorten the time for constructing our data structures.
(
(
$&/.
$&/.
$&/.
$&/.
$&/.
$&/.
(
(
(
(
(
(
(
(
(
(
,WHUDWLRQ
,WHUDWLRQ
(a) Prefix Length Tuples
(b) Nested Level Tuples
Figure 1. The size of cross-product table in each iteration of tuple selection for ACL1.