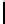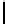Information Technology Reference
In-Depth Information
of distinct and unique prefixes in
T
j
, where the
unique
prefixes only appear in
T
j
. With
unique(P
T
i
)
, we can derive the number of cross-product entries for the filters not in
T
j
as
C
0
=
Q
i=1
(P
i
− unique(P
T
i
))
. Since our algorithm attempts to reduce the value of
C
0
to
less than
C
threshold
, in the fourth step, we repeatedly select one tuple which can yield the
minimum
C
0
value until
C
0
≤ C
threshold
. In each iteration, we update the value of
P
i
as
P
i
= P
i
− unique(P
T
i
)
. Also, the number of unique prefixes of each tuple might change
due to the fact that the other filters that specify the same prefixes belong to the tuples which
have been selected in the previous iterations.
Note that our procedure of selecting tuples may not be optimal since we cannot calculate
all combinations of tuple selections. The number of tuple selection combinations is equal
!
!
!
|TS|
1
|TS|
2
|TS|
|TS|−1
+
+ ...+
, where
|TS|
is the number of original
to
tuples. The problem of tuple selection is analogous to the facility location problem and can
be modeled as a
p
-median problem [25]. This model is also known as a knapsack model,
which is NP hard [25]. Therefore, we employ a greedy algorithm to simplify the calculation.
Our experimental results demonstrate that the proposed algorithm could effectively reduce
the cross-product entries while maintaining the number of tuples low.
We use the filters in Table 1 as an example to illustrate our procedure for tuple selection.
We assume that
C
threshold
equals
ten
. Table 2
∼
4 lists three iterations of calculating the
number of the resulted cross-product entries. Initially, the value of
P
1
is
eight
and that
of
P
2
is
seven
. Therefore, the number of cross-product entries,
C
, is equal to 56. In the
first iteration, selecting the filters from
T
3,2
would reduce the maximum number of cross-
product entries, where there are 30 entries left in the cross-product table. After removing
the filters in
T
3,2
, the values of
P
1
and
P
2
are then updated to
five
and
six
, respectively.
Since the value of
C
0
is 30, another iteration of tuple selection is activated.
Table 2. The First Iteration of Tuple Selection for the Filters in Table 1.
(
P
1
=8,P
2
=7
)
unique
(
P
1
)
unique
(
P
2
)
P
1
−
unique
(
P
1
)
P
2
−
unique
(
P
2
)
Tuple
Filters
T
0
,
4
F
1
,F
2
1
2
7
5
T
1
,
1
F
3
0
1
8
6
T
1
,
2
F
4
0
0
8
7
T
2
,
2
F
5
1
0
7
7
T
3
,
2
F
6
∼
F
9
3
1
5
6
T
4
,
0
F
10
,F
11
2
1
6
6
In the second iteration, the values of
unique(P
1
)
and
unique(P
2
)
for the remaining
tuples are updated. For example, the value of
unique(P
T
1
,
2
)
is changed from 0 to 1 since
the other two filters,
F
6
and
F
8
, which specify “
01∗
”on
f
2
, both belong to
T
3,2
and have
been removed in the first iteration. Our algorithm would select
T
4,0
in this iteration, and the
values of
P
1
and
P
2
are then updated to
three
and
five
, respectively. The resulted value of
C
0
is equal to 15; thus, the third iteration of tuple selection is required. After updating the
values of
unique(P
1
)
and
unique(P
2
)
,
T
0,4
is selected and the number of cross-product
entries is reduced to
six
which is smaller than
C
threshold
. As a result, there remain three