Database Reference
In-Depth Information
Fig. 16.4 A modified decision tree for recommender systems.
the two groups. However, different splits may result in different group
sizes. Comparing the size of the intersection between splits of different
sub-relation sizes would not be sucient since an even split for example
(half the tuples in group
A
and half in group
B
) would probably have a
larger intersection than a very uneven split (such as one tuple in group
A
and all the rest in group
B
). Instead, we look at the probability of our
split's item-intersection size compared to a random (uniform) split of similar
group sizes. A split which is very likely to occur even in a random split is
considered a bad split (less preferred) since it is similar to a random split
and probably does not distinguish the groups from each other. A split that
is the least probable to occur is assumed to be a better distinction of the
two subgroups and is the split selected by the heuristic.
More formally let us denote:
•
items
(
S
)=
π
ItemID
(
S
), where
π
is the projection operation in relational
algebra, the set of all
ItemIDs
that appear in a set
S
.
•
O
i
(
S
)=
,where
σ
is the select operation in relation
algebra, is the number of occurrences of the
ItemID i
in the set
S
.
|
σ
ItemID
=
i
(
S
)
|
Let
S
q
(
q
denotes the number of ratings) be a random binary partition
of the tuples in
Ratings
into two sub-relations
A
and
B
consisting of
k
and
q
k
tuples, respectively. We are interested in the probability distribution
of
S
q
≡|
−
(
items
(
A
)
items
(
B
)
|
.








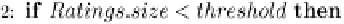



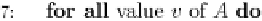


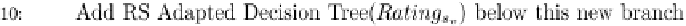
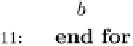




Search WWH ::

Custom Search