Database Reference
In-Depth Information
Fig. 13.1 Pseudo-code of independent algorithmic framework for feature selection.
algorithm on its corresponding dataset. The various feature subsets are then
combined into a single subset.
13.5.2
Combining Procedure
We begin by describing two implementations for the combiner component.
In the literature, there are two ways of combining the results of the
ensemble members: weighting methods and meta-learning methods. Here,
we concentrate on weighting methods. The weighting methods are best
suited for problems where the individual members have comparable success
or when we would like to avoid problems associated with added learning
(such as over-fitting or long training time).
13.5.2.1
Simple Weighted Voting
Figure 13.2 presents an algorithm for selecting a feature subset based on
the weighted voting of feature subsets. As this is an implementation of the
abstract combiner used in Figure 13.1, the input of the algorithm is a set of
pairs; every pair is built from one feature selector and a training set. After
executing the feature selector on its associated training set to obtain a
feature subset, the algorithm employs some weighting method and attaches
a weight to every subset. Finally, it uses a weighted voting to decide which
attribute should be included in the final subset. We considered the following
methods for weighting the subsets:
(1)
Majority Voting
— In this weighting method, the same weight is
attached to every subset such that the total weights is 1, i.e. if there
are
ω
subsets then the weight is simply 1/
ω
. Note that the inclusion
of a certain attribute in the final result requires that this attribute will
appear in at least
ω
/2 subsets. This method should have a low false
positive rate, because selecting an irrelevant attribute will take place
only if at least
ω
/2 feature selections methods will decide to select this
attribute.









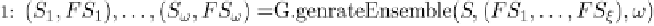

Search WWH ::

Custom Search