Database Reference
In-Depth Information
the training set and learning a classifier on each; estimating each class's
probability for each example by the fraction of votes that it receives from
the ensemble. It then relabels each training example with the estimated
optimal class, and reapplies the classifier to the relabeled training set.
12.4
Induction of Cost Sensitive Decision Trees
In this section we present the algorithm proposed in [Ling
et al
. (2006)].
The proposed algorithm takes into account the misclassification costs, and
the attribute costs. It selects attributes according to the expected reduction
in the total misclassification cost. If the largest expected cost reduction is
greater than 0, then the attribute is chosen as the split (otherwise, it is not
worth building the tree further, and a leaf is returned). Figure 12.1 presents
the algorithm.
For the sake of simplicity we assume that there are only two classes.
The notations
CP
and
CN
represent the total misclassification cost of
being a positive leaf or a negative leaf respectively. If
C
(
P, N
)isthecost
of false positive misclassification, and
C
(
N, P
) is the cost of false negative
misclassification, then
CP
=
C
(
P, N
)
FN
is the
total misclassification cost of being a negative leaf, and the probability of
·
FP
and
CN
=
C
(
N, P
)
·
Fig. 12.1 Algorithm for inducing cost sensitive decision trees.







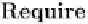





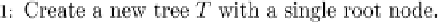


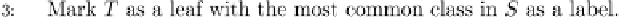
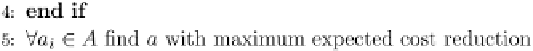







Search WWH ::

Custom Search