Database Reference
In-Depth Information
of the original. The transformation guarantee that the first principal
component has the largest possible variance. Every subsequent component
has the highest variance possible under the constraint that is orthogonal to
the previous components.
The principal components is used to construct the new set of features.
The original dataset is transformed linearly into the new feature space to
construct the new training set. This new training set is fed into the tree
induction algorithm which train a classification tree. Note that different
feature partitions will lead to different set of transformed features, thus
different classification trees are generated.
Figure 9.14 presents the Rotation Forest pseudocode. For each one
of the
T
base classifiers to be built, we divide the feature set into
K
Fig. 9.14 The rotation forest.








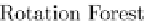

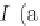
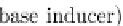













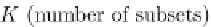























































































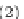

















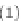

























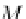








Search WWH ::

Custom Search