Database Reference
In-Depth Information
Fig. 9.9 The AdaBoost.M.1 algorithm.
All boosting algorithms presented here assume that the weak inducers
which are provided can cope with weighted instances. If this is not the case,
an unweighted dataset is generated from the weighted data by a resampling
technique. Namely, instances are chosen with a probability according to
their weights (until the dataset becomes as large as the original training set).
Boosting seems to improve performance for two main reasons:
(1) It generates a final classifier whose error on the training set is small by
combining many hypotheses whose error may be large.
(2) It produces a combined classifier whose variance is significantly lower
than those produced by the weak learner.
On the other hand, boosting sometimes leads to a deterioration in
generalization performance. According to Quinlan (1996), the main reason
for boosting's failure is overfitting. The objective of boosting is to construct
a composite classifier that performs well on the data, but a large number
of iterations may create a very complex composite classifier, that is
significantly less accurate than a single classifier. A possible way to avoid
overfitting is by keeping the number of iterations as small as possible. It









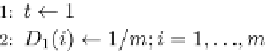
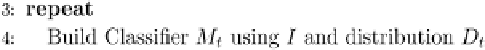
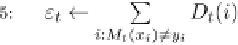
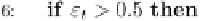

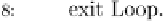
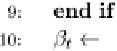

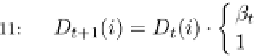
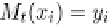
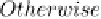
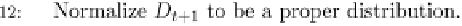
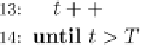

Search WWH ::

Custom Search