Database Reference
In-Depth Information
(7) When classification cost is high, decision trees may be attractive in that
they ask only for the values of the features along a single path from the
roottoaleaf.
Among the disadvantages of decision trees are:
(1) Most of the algorithms (like ID3 and C4.5) require that the target
attribute will have only discrete values.
(2) As decision trees use the “divide and conquer” method, they tend to
perform well if a few highly relevant attributes exist, but less so if many
complex interactions are present. One of the reasons for this happening
is that other classifiers can compactly describe a classifier that would be
very challenging to represent using a decision tree. A simple illustration
of this phenomenon is the replication problem of decision trees
[
Pagallo
and Huassler (1990)
]
. Since most decision trees divide the instance space
into mutually exclusive regions to represent a concept, in some cases
the tree should contain several duplications of the same subtree in order
to represent the classifier. The replication problem forces duplication of
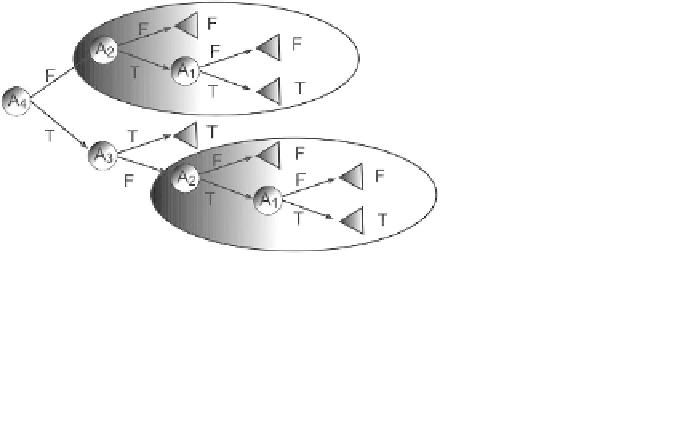
subtrees into disjunctive concepts. For instance, if the concept follows
the following binary function:
A
3
∩
A
4
) then the minimal
univariate decision tree that represents this function is illustrated in
Figure 7.1. Note that the tree contains two copies of the same subtree.
(3) The greedy characteristic of decision trees leads to another disadvantage
that should be pointed out. The over-sensitivity to the training set,
to irrelevant attributes and to noise
[
Quinlan (1993)
]
make decision
trees especially unstable: a minor change in one split close to the root
will change the whole subtree below. Due to small variations in the
y
=(
A
1
∩
A
2
)
∪
(
Fig. 7.1
Illustration of decision tree with replication.







Search WWH ::

Custom Search