Databases Reference
In-Depth Information
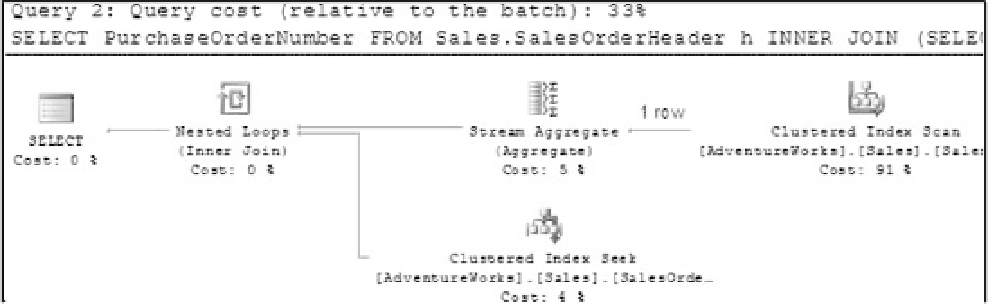
Figure 9-18
Join can occur, the optimizer chooses to use this grouping structure to maintain the order by the groups.
This removes the need for the Sort step that was required for the first query method. Maintaining a sort
is more efficient than writing the results and then resorting.
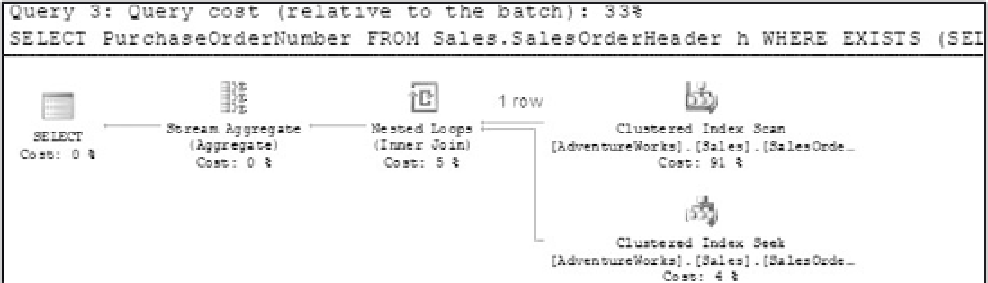
Many people think that correlated subqueries are the most efficient. When you examine this last method
it may seem like the best combination of the two previous methods. In fact, the first three steps are the
same. The difference is that a GROUP BY operation is used by the Stream Aggregate to build the sorted
output for each SalesOrderId to avoid an additional sort. You can see this in the plan in Figure 9-19.
Figure 9-19
Here's where you have to start digging. Relative to all three techniques, the derived and correlated
subqueries with query costs of 33 percent look equivalent. Remember that we are talking about costs,
not speed, so before a final choice is made, you should look at the details provided by the profiler and
reevaluate with a less selective WHERE predicate to see how each solution scales.
In the profiler under the Showplan Statistics Profile Event class, both methods display essentially the
same estimates for subtree costs of 1.15691. The actual results can be determined by looking into the
CPU, Reads, Writes, and Duration columns. The results, presented in Table 9-25, show that the overall
duration of the derived table is statistically the same as correlated subquery and almost 40 percent faster
than the full join summarization.













Search WWH ::

Custom Search