Databases Reference
In-Depth Information
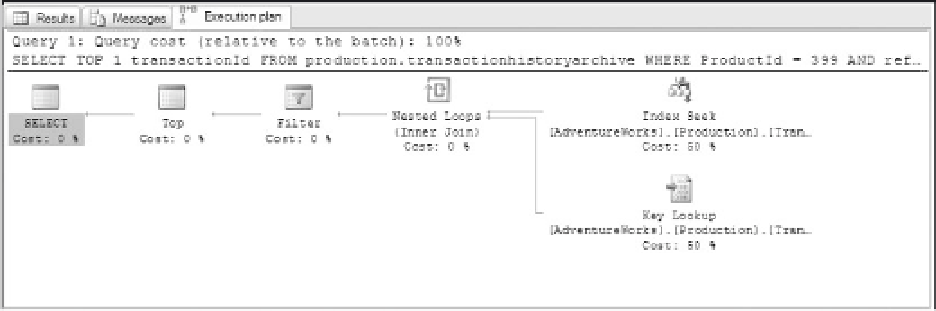
Figure 9-14
Another way to perform the same action is to use an aggregate function. An example of the same query
written with an aggregate
MAX
function would look like this:
SELECT max(transactionId)
FROM production.transactionhistoryarchive
WHERE ProductId = 399
AND referenceOrderId = 5633
AND transactiondate = '2001-11-18 00:00:00.000'
AND quantity
>
2
AND actualcost
>
=0
If you looked at the execution plan for this query, you'd notice that the optimizer applied the same access
methodology of using the referenceOrderId field index, but added a Stream Aggregate operator instead
of a Top operator. Statistically, the sub costs are insignificant. This is partly because the index produces
only one row to work with. The costing formulas used by the optimizer estimate the Stream Aggregate
operator to be slightly more expensive (.0000011% compared to .0000001%) , but if you view the queries
using the profiler, you'll see that the CPU and I/O page reads are exactly the same.
Now look at what happens if you change the query to return the whole row. Change the first query
from ''
SELECT TOP 1 transactionId
'' to ''
SELECT TOP 1 *
''. For the second query, a typical rewrite would
use a derived table to first get the maximum transactionId and then retrieve the row like this:
SELECT *
FROM production.transactionhistoryarchive
WHERE transactionid = (
SELECT max(transactionId)
FROM production.transactionhistoryarchive
WHERE ProductId = 399
AND referenceOrderId = 5633
AND transactiondate = '2001-11-18 00:00:00.000'
AND quantity
>
2
AND actualcost
>
=0
)
When you run the two side by side, you'll notice that the estimated costs will display query costs of
6 percent for the
TOP
query and 35 percent for the
MAX
query. However, when you look into the profiler,












Search WWH ::

Custom Search