Databases Reference
In-Depth Information
The Sales.SalesOrderDetail table has the indexes listed in Table 9-22. The index starting with PK% is
clustered; the IX% index is not.
Table 9-22: Indexes on SalesOrderDetail Table
Index Name
Columns
IX_SalesOrderDetail_ProductID
ProductID
PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID
SalesOrderID, SalesOrderDetailID
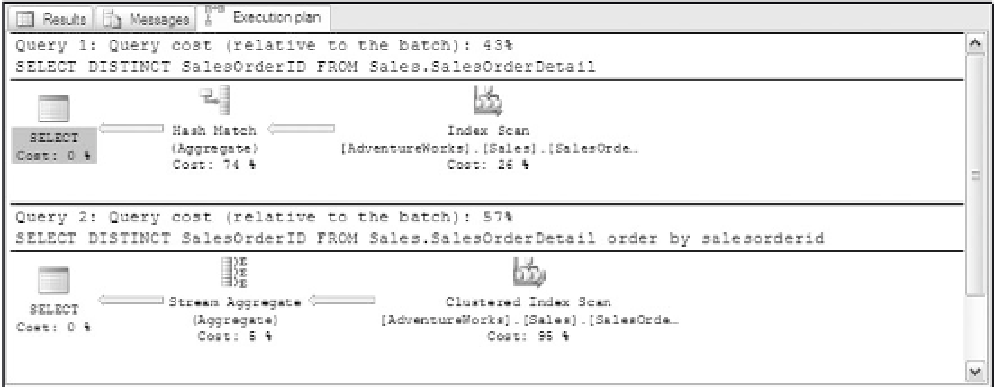
You might expect that the scan for the SalesOrderID should occur on the clustered index field. This is,
of course, one of the mantras of performance tuning — make sure you are using clustered indexes when-
ever possible. If you look at the query plan in Figure 9-13, you'll see that the non-clustered index by
ProductId is being used. If you tinker with the plan by adding an ORDER BY statement, you can force the
optimizer to use a clustered index scan instead. This equivalent action would be taken if the non-clustered
index by ProductId did not exist.
Figure 9-13
Although the costs of the two plans are close, the I/O numbers are far apart. Query 1 using the non-
clustered index produces 228 logical page reads, compared to the clustered index 1,783 page reads of
Query 2. What is happening here is that the non-clustered index is functioning as a covering index, since
it contains both the ProductId and the SalesOrderId for each row in the table. More rows of this index
can fit into an 8K page than from the clustered index. Remember that the clustered index leaf contains
the page itself and in this case requires 7.5 times more pages to be loaded into memory to perform the
DISTINCT
operation. It is clear that you would
not
want to add the extra ORDER BY clause into this T-SQL
statement to achieve a Clustered Index Scan operation to incur this extra cost. Look for non-clustered
indexes on tables where you may be performing consistent DISTINCT operations to ensure that you
aren't creating this performance issue.
















Search WWH ::

Custom Search