Databases Reference
In-Depth Information
Denormalization
No description of normalization can be complete without including a word about denormalization (or as
I like to call it ab-normalization!). This term is somewhat misleading. It doesn't mean that a table will or
can be created outside the rules of normalization. It means that a schema can be ''downgraded'' from a
higher normal form (say 4NF) to a lower normal form (say 2NF).
Denormalizing a group of tables should be carefully considered before proceeding. The reason is that
as the schema descends the normalization scale, the anomalies which normalization seeks to eliminate
start ascending. In short, denormalization can be interpreted to mean that data quality is less important
than data retrieval.
However, there is certainly a place for denormalized data structures, which is typically in support of
decision support systems or data warehouses. Any system that provides a high degree of reporting and
data retrieval is a prime candidate for denormalization. In these applications, data retrieval takes priority
over data writing. Therefore, the anomalies that normalization seeks to squelch aren't deemed to be
an issue.
In fact, many organizations will have both types of databases present. They'll have a highly
normalized database, known as an online transactional process (OLTP) style. They'll also have a
highly denormalized database, known as an online analytical process (OLAP) style. These organizations
will use the OLTP database to populate the OLAP database. This provides the best of both worlds. The
OLTP database will function to quickly and accurately capture the data, and the OLAP database will
function to quickly and accurately produce reports, queries, and analytical capabilities.
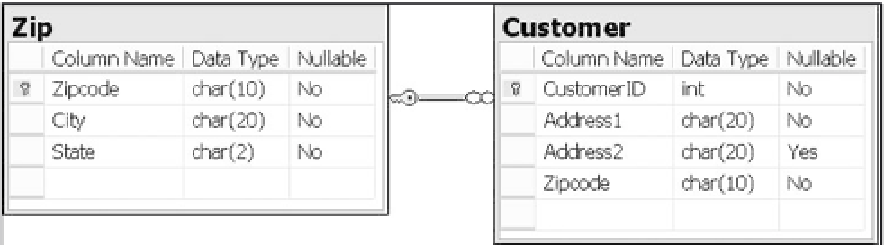
For a quick illustration of these differences consider the model of a normalized structure shown in
Figure 8-7 and the model of a denormalized structure shown in Figure 8-8.
Figure 8-7
Notice that in the second structure the Zip table has been removed entirely. The City and State columns
have been moved into the Customer table. Because of this, those columns are prone to writing anomalies,
which isn't an issue in the first structure. However, querying and retrieval are simpler in the second
structure. Conversely, that is a more difficult task with the first structure because of the need for joining
two tables.
One of the main reasons for denormalizing is to provide a performance edge when retrieving data.
Denormalization means that there will be fewer tables in the schema, therefore fewer joins. The idea is
that fewer joins will result in better performance. For example, if the data is in four tables as opposed to
being in a single row of one table, you will incur four physical I/Os, four pages in buffer pool, and so on.












Search WWH ::

Custom Search