Biology Reference
In-Depth Information
such as the 1000 genomes project
[57]
; the International
Cancer Genome Consortium
[58]
; etc. Version 7 (2011)
includes approximately 138 000 transcript models at 20 687
protein-coding and 9640 long non-coding RNA loci.
In 2006 the groups mentioned above (NCBI (RefSeq),
UCSC, WTSI (Havana) and Ensembl) identified a need to
collaborate and produce a consensus gene set for the human
reference genome, since there was still no official agreement
between the different databases on the human protein-
coding genes. Referred to as the Consensus Coding
Sequence Set (CCDS), it only contains coding transcripts
that are equivalent in each database's gene build from start
codon to stop codon. Version 37.3 of CCDS (September
2011) contains 26 473 transcripts that correspond to 18 471
genes. The CCDS set constitute the most solid set of protein-
coding gene sequences available for the human genome.
The Protein-coding Transcriptome
Current gene numbers in human (and other species) should
be taken only as indications. Although the number of
human protein-coding genes
is unlikely to change
substantially
albeit not the number of transcripts gener-
ated from these loci
e
the number of long non-coding RNA
loci is essentially unknown, and as RNASeq analysis is
performed in an increasingly large number of tissues and
cell types it is likely to increase substantially.
Protein-coding and long non-coding RNAs, as well as
other classes of small RNAs, are organized along the
genome in a complex network of interleaving transcripts,
challenging our long-prevailing notion of genes as separate
and well defined entities (
Figure 2.3
). Indeed, about 8500
genes annotated in GENCODE encode transcripts that
e
-50Kb
0Kb
50Kb
100Kb
150Kb
200Kb
250Kb
300Kb
350Kb
400Kb
450Kb
500Kb
550Kb
600Kb
650Kb
<AC
019011
.1>
<AC01
1
330.1>
<AC01
13
30.7>
<AC01
8512.1>
<
AC0185
12.5>
<AC018512.7>
<AC023356.1>
-50Kb
0Kb
50Kb
100Kb
150Kb
200Kb
250Kb
300Kb
350Kb
400Kb
450Kb
500Kb
550Kb
600Kb
650Kb
<AC011330.3>
<AC019011.2>
<AC011330.2>
<AC018512.4>
<AC018512.0>
<AC018512.8>
<AC023356.2>
<AC018924.1>
<AC011330.4>
<AC018512.2>
-50Kb
0Kb
50Kb
100Kb
150Kb
200Kb
250Kb
300Kb
350Kb
400Kb
450Kb
500Kb
550Kb
600Kb
650Kb
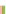
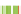
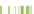
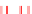
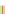
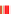
FIGURE 2.3
Transcriptional complexity in the human genome. Transcriptional map of a 650 Mb region in the human genome. This region starts
approximately at position 41 520 000 on human chromosome 15, and corresponds roughly to the region corresponding to the region referred to as ENr233
in the pilot phase of the ENCODE project
[54]
. Blue triangles represent gene loci, and connected boxes represent transcripts. Each box corresponds to an
exon. Green boxes correspond to protein-coding exons. Transcripts corresponding to loci encoded in the forward strand of the DNA sequence are dis-
played above the x-axis at the center of the display. Transcripts corresponding to loci in the reverse strand are displayed below. The map illustrates the
transcriptional complexity of the human genome, with loci encoding a mixture of coding and non-coding transcripts, and transcripts themselves often
overlapping multiple loci.