Database Reference
In-Depth Information
distribution. Individual attribute values therefore bear no similarity to the original
values, e.g. salary values may become negative numbers. The distribution of such
randomized attribute is of course totally different from the original distribution of
a
j
, but (Agrawal and Srikant 2000) show how its distributional properties can be
reconstructed from the randomized distribution so that meaningful data mining
operations (e.g. classification, or association rules) can be performed. This is illu-
strated in Fig. 2. The results of these data mining operations are close to the results
obtained on the original data. This approach of (Agrawal and Srikant 2000) has
been shown to be prone to an attack, using sophisticated control theory methods
(Kargupta, Datta et al. 2003). Another perturbative approach introduces multiplic-
ative rather than additive noise in the data (Kun, Kargupta et al. 2006), with priva-
cy guarantees stronger than those given by additive noise.
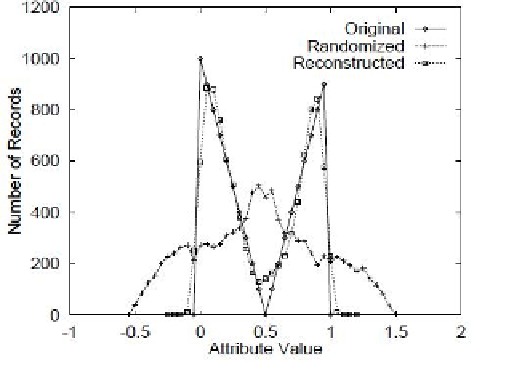
Fig. 11.2
The effects of the perturbation the distribution of the attribute being perturbed, to
protect the disclosure of its values (from (Aggarwal and Yu 2008)). The curve labeled
“randomized” has a distribution very different from the original one. Data mining is per-
formed on the reconstructed distribution, obtained using the algorithm described in the pa-
per. The reconstructed distribution close is to the original, and therefore the results of data
mining are close to what they would have been on the original, confidential.
Perturbative methods have the disadvantage of modifying the original data,
which can be difficult to accept in certain classes of applications, e.g. in working
with medical data.
A different kind of perturbative approach is known as
rank swapping
(Nin,
Herranz et al. 2008). The main idea is to swap values of a given attribute among
records in a dataset. The swapping is controlled by the distance between the
swapped values - values that are close are more likely to be swapped. The advan-
tage of this approach is that, unlike with the noise-injecting approaches described
above, the entire set of values of a given attribute and its distribution are pre-
served. The disadvantage is that potentially implicit relationships between values
of attributes can be broken.
Search WWH ::

Custom Search